Этим постом мы хотели бы начать цикл статей, посвященных задаче изменения голоса. В зарубежной литературе данную задачу часто именуют термином voice morphing, в отечественной литературе данная задача ещё не получила достаточного освещения как в научных, так и в инженерных кругах. Тема является достаточно обширной и во многом творческой. В результате работы в данном направлении у нас накопился определенный опыт, который мы планируем систематизировать и изложить, а также передать основную суть некоторых алгоритмов.
Изменение голоса может преследовать разную цель. Два основных направления, которые тут однозначно можно выделить – это получение реалистичного звучания измененного голоса и получение некоторого причудливо-фантастичного звучания. Неплохих результатов во втором случае вполне можно добиться, обрабатывая речевой сигнал как обычный звук, не заостряя внимание на его особенностях и делая многие допущения. Например, индустрия электронной музыки породила колоссальное количество разнообразных аудио-эффектов и результат их применения к речевому сигналу помогает создать самый невероятный образ говорящего.
В задаче реалистичного изменения голоса применение «музыкальных» (назовем их так) аудио-эффектов может привнести искажения, не характерные для натуралистичного звучания речи. В подобном случае необходимо более точно понимать, из каких звуков состоит речь, как они образуются и какие их свойства являются критическими для восприятия. Проще говоря — необходимо производить анализ сигнала перед его обработкой. При автоматизированной обработке речевого сигнала в реальном времени этот анализ усложняется многократно, т.к. умножается количество неопределенностей, которые надо как-то попытаться разрешить, и сокращается количество применимых алгоритмов.
В ближайших статьях мы рассмотрим варианты простейшей реализации таких эффектов, как изменение пола говорящего и изменение возраста говорящего. Чтобы читатель лучше понимал, какие параметры сигнала будут изменяться, в первых статьях будут затронуты основные вопросы образования звуков речи и способы формального описания речевого сигнала. После этого уже будут обсуждаться конкретные предлагаемые алгоритмы изменения голоса, их сильные и слабые стороны.
Введение
Если рассматривать звуки речи отдельно друг от друга, на первый взгляд может показаться, что ничего особенного они из себя не представляют — типичный гласный звук по сути не так уж и далек от звука, скажем, флейты. Однако обработка отдельно стоящих «в вакууме» звуков вряд ли многим принесет практическую пользу — гораздо более привлекательной затеей выглядит обработка слитного речевого сигнала. Вдвойне привлекательной кажется идея натуралистичного звучания обработанной речи. Данная задача уже значительно сложнее — в натуральной слитной речи звуки настолько быстро и плавно перетекают один в другой, что даже человек с опытом не всегда может четко поставить границу при обработке. А если ко всем звукам речи подходить одинаково — никакого натурального звучания не выйдет.
Речевой сигнал является более «разносторонним», если можно так выразиться, сигналом, нежели например звук музыкальных инструментов. Занимая сравнительно узкую частотную полосу, речь состоит из огромного разнообразия элементарных звуков, которые вдобавок могут коартикулировать самым причудливым образом даже в обыденной речи, не говоря уже об осознанном изменении голоса профессиональным актером. При этом эти элементарные звуки имеют разную природу и, как следствие, разные характеристики с точки зрения стандартных алгоритмов анализа и обработки сигналов.
Речевой тракт человека является едва ли не наиболее совершенным и гибким в сравнении со всеми известными животными и по разнообразию производимых звуков оставляет позади большинство музыкальных инструментов. Основная сложность в анализе и изменении голосового сигнала кроется именно в данном разнообразии и вытекающей большой неопределенности, связанной с вычленением и обработкой элементарных звуковых единиц. Не существует алгоритмов, хорошо подходящих для обработки всех звуков речи. К тому же, один и тот же элементарный звук человек может произносить по-разному в зависимости от своего эмоционального, физического состояния, от места звука в слове, etc. Индивидуальные особенности произношения, культурный и языковой фактор, медицинские патологии — все это также оказывает влияние на произносимый звук.
Звукообразование, общие сведения
Для понимания специфики обработки голосового сигнала, рассмотрим более подробно вопрос звукового состава речи и каким образом данные звуки образуются. Процесс звукообразования принято описывать с помощью двух основных понятий: фонация и артикуляция, опишем их по порядку.
Фонация — часть процесса звукообразования, происходящая в гортани человека. Начинается все с сжатия легких — это приводит в движение воздух, который из легких через трахею поступает в гортань. Данный воздушный поток имеет практически постоянную, медленно меняющуюся скорость. В гортани находится голосовая щель, образуемая двумя голосовыми складками, к которым «прикреплены» голосовые связки. При напряжении связок голосовая щель периодически смыкается/размыкается и формирует таким образом воздушные импульсы из входного воздушного потока. Каждый импульс можно описать объемной скоростью воздуха, который проходит через голосовую щель, обозначим её мгновенное значение как U(t). Человеческое ухо воспринимает колебания в давлении, которые пораждаются изменением скорости воздушного потока, и нас, таким образом, более интересует первая производная от объемной скорости — dU/dt. Для более наглядной иллюстрации можно обратить внимание на картинку ниже. Показана модель U(t) и её первая производная, оба графика полученны с помощью модели Розенберга:
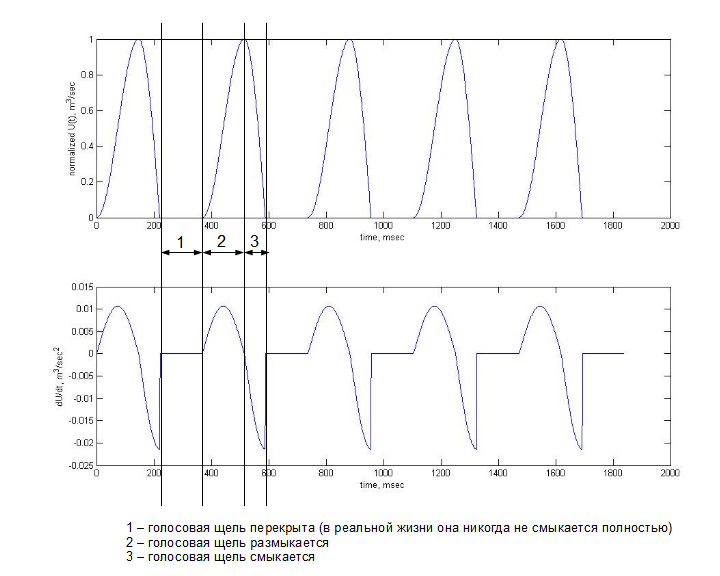
Верхний график отражает значение U(t) во времени на выходе голосовой щели. Нижний график показывает первую производную U(t) по времени — суть изменение давления на выходе голосовой щели. Это периодическое изменение давления уже является звуком само по-себе. Данный звук состоит из шумовой и гармонической составляющих. Шумовая составляющая образуется турбулентностью из-за резкого увеличения U(t) и неполного смыкания голосовой щели (модель на картинке выше не учитывает шумовую составляющую). Гармоническая составляющая может быть представлена гармоническим рядом, где частоты всех вторичных гармоник (которые ещё называют обертонами) кратны частоте первой самой низкой гармоники, называемой частотой основного тона. (см. рисунок ниже).
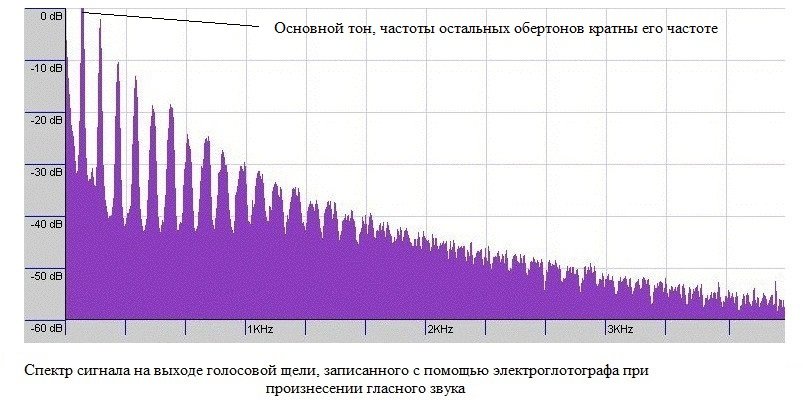
Физику образования данных гармоник в двух словах объяснить не получится, для этого лучше написать отдельную статью. Главное пока запомнить, что из гортани при работе связок уже может выходить вполне гармонический звук. Численное значение частоты основного тона равно частоте сокращения голосовых связок и является функцией от их длины, плотности и натяжения.
При расслабленных связках и постоянно открытой голосовой щели воздушный поток ничем не «нарезается», если можно так выразиться, скорость воздуха в таком случае слабо колеблется около некоторого постоянного значения и формируемый звук имеет шумовую природу, пример спектра данного сигнала приведен ниже.

Результатом фонации является некий звук, который часто называют «сигналом возбуждения голосового тракта». Из этого базового сигнала (гармонического или нет) по мере его прохождения через голосовой тракт далее будет формироваться конечный звук, который мы слышим при разговоре.
Краткое резюме: главный «инструмент» фонации — две голосовые складки, которые образуют собой голосовую щель и которые приводятся в движение голосовыми связками. Связки могут периодически сокращаться или находиться в расслабленном состоянии, что приводит к образованию вокализованного или невокализованного звуков соответственно.
Исследованию фонации, особенно вокализованной, посвящено огромное количество работ, рассматривающих данный процесс с самых разных точек зрения — механической, термодинамической, акустической, статистической, психоакустической. Достоверно установлено, что неидеальность формируемых воздушных импульсов при вокализованной фонации, случайное изменение их формы и частоты, сильно влияет на натуральность звучания. Для примера можно послушать звук по приведенной ссылке — он как раз синтезирован с помощью модели с первого рисунка, а также параметров речевого тракта автора статьи, при произнесении звука «А». Не думаю, что кому-то данный звук покажется «живым» и натуральным. Человеческое ухо достаточно точно определяет звук, синтезированный с помощью искусственного сигнала возбуждения, что значительно повышает значимость статистического исследования данного процесса.
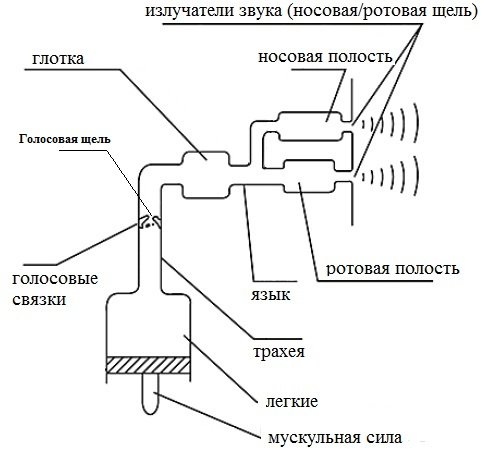
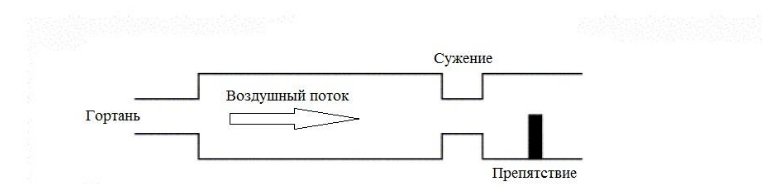
Артикуляция заключает в себе процесс изменения состояния всех элементов речевого тракта при звукопроизнесении. Фонация является частью артикуляции. Речевой тракт можно упрощенно представить совокупностью камер и трубок (см. рисунок справа), через которые проходит сигнал возбуждения. Сужения и расширение смычек голосового тракта, лежащих выше гортани, дополнительно влияют на скорость прохождения воздушного потока, формируют дополнительные (помимо голосовой щели) зоны турбулентности. Вместе с тем полости речевого тракта аналогичны акустическим резонаторам при прохождении через которые усиливаются одни и ослабляются другие частоты звука. Мышцы речевого тракта позволяют человеку контролировать геометрию камер речевого тракта, создавать препятствия на пути воздушного потока (язык, зубы, губы).
В грубом приближении можно резюмировать вышесказанное, как:
артикуляция = фонация + работа мышц речевого тракта,
где фонация может быть вокализованной или не вокализованной, а сокращение каждой отдельной мышцы — некоторая функция от времени.
В процессе обучения разговорной речи человек учится координировать работу органов артикуляции для получения определенных звуков. Из-за индивидуальных анатомических особенностей один и тот же звук у всех людей звучит немного по-разному, и это один из важных факторов, по которым мы отличаем голоса людей. При согласованной работе голосовых связок и остальных мышц речевого тракта, возможно образование гласных, согласных, смешанных и переходных звуков. Далее предлагается кратко рассмотреть эти группы, в общих чертах описать их артикуляцию и основные признаки.
Простейшая классификация звуков речи
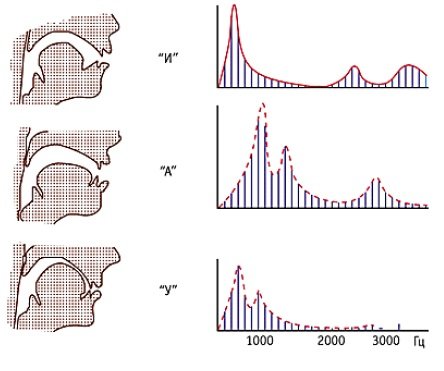
Со школы известно, что все звуки речи изначально принято делить на гласные и согласные. Гласные звуки формируются при прохождении вокализованного сигнала возбуждения от голосовой щели через остальной речевой тракт, который при этом занимает некоторую фиксированную геометрическую форму. Этот процесс во многом подобен тому, как звук колеблющейся струны проходит через корпус гитары. В случае с человеческим голосом, «струной» выступает периодически сокращаемая голосовая щель, а корпусом — все, что выше её. Если представить себе, что корпус гитары может принимать одну из нескольких «заранее выученных» форм, то возможно провести аналогию с гласными звуками: гортань создает вокализованный сигнал возбуждения, а речевой тракт принимает одну из форм, в итоге получается гласный звук.
Меняя геометрию речевого тракта, человек меняет его акустические резонансные свойства. В итоге некоторые частоты усиливаются, некоторые напротив заметно ослабляются. Зоны усиления принято называть формантными частотами или формантами. Гласные звуки отличаются друг от друга именно своей формантной структурой (см. рисунок справа), зависящей от геометрии речевого тракта в момент речеобразования — именно так их и различает человек на слух. Точные численные значения формантных частот индивидуальны для каждого человека. Однако их относительное расстояние между друг другом имеет примерно одинаковые пропорции у всех людей (иначе как бы мы могли распознать, например, звук «О», произносимый разными людьми).
Теперь перейдем к согласным звукам. Их количество значительно превышает количество гласных звуков и по своему звучанию они могут быть разбиты на подклассы. Как это часто бывает в реальной жизни, многие феномены имеют признаки многих классов и однозначная классификация весьма затруднительна. Согласные звуки в данном случае не являются исключением. Их разбиение на классы зависит от рассматриваемого языка и применяемой фонетической теории. Мы рассмотрим наиболее общую классификацию, состояюшую из трех основных групп:
— фрикативные согласные
— смычные согласные
— сонорные согласные
Фрикативные согласные образуются «трением» воздушного потока о сужения речевого тракта и препятствия на пути следования воздуха. Данные сужения и препятствия могут быть созданы небом, языком, зубами, губами, etc (звуки Ф, Х, Ш, С …). Полости речевого тракта при этом занимают некоторую (условно)фиксированную позицию. Сужения и препятствия вызывают локальные изменения в давлении воздушного потока, что в свою очередь создает зоны турбулентности. Порождаемый таким образом турбулентный шум уже не белый — он имеет окрас
Генерируемый шумовой сигнал, как и в случае с гласными звуками, проходит через некоторое количество акустических фильтров (камеры речевого тракта), которые придают этому шуму некоторую характерную спектральную форму и звучание.
Смычные согласные образуются путем полного перекрытия речевого тракта каким-либо органом артикуляции при открытой голосовой щели. При этом воздух, поступающий из легких через открытую голосовую щель, нагнетает давление и при резком размыкании препятствия создает «взрывной» звук (звуки K, П, Т …). Например при произнесении звука «П», человек смыкает губы, но легкие при этом продолжают нагнетать давление. Затем губы резко размыкаются и создаваемый скачкообразный перепад в давлении порождает знакомый всем звук «П». Изображение во временной области представлено ниже:
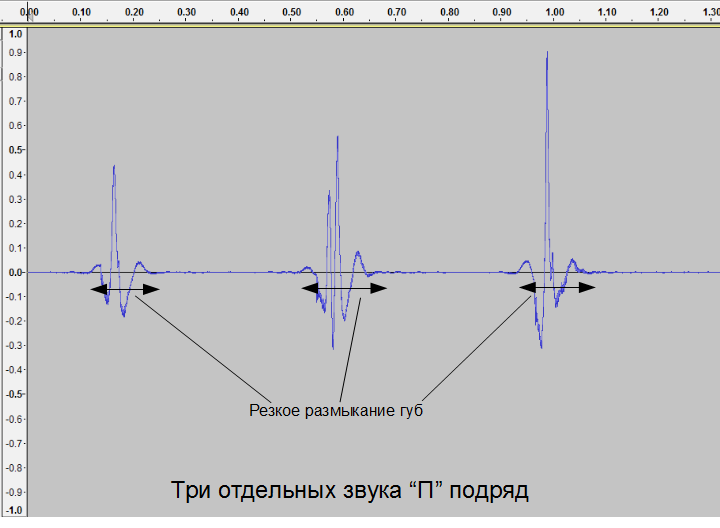
Следует обратить внимание, что все три попытки произношения звука значительно отличаются друг от друга во временной области. При этом на слух их отличить весьма тяжело.
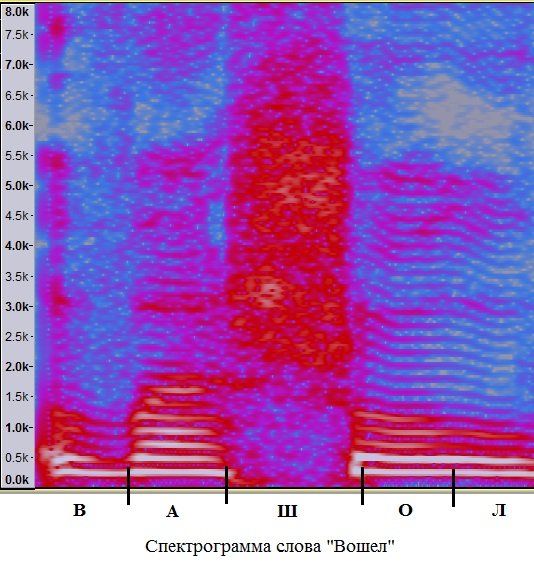
Пример спектрограммы слова с несколькими смычными звуками изображен ниже.

Также нельзя не отметить, что и фрикативные, и смычные согласные могут быть «звонкими». «Звонкие» согласные по своей природе являются смешанными звуками, образуемыми путем произнесения согласного звука одновременно с работой голосовых связок. Например, если проделать действия, описанный при произнесении звука «П» и добавить при этом работу голосовых связок, то получится звук «Б». Однако нельзя утверждать, что они являются простой суперпозицией некоторого гласного и некоторого согласного звука во временной области. Нельзя просто взять записать звук «С», сложить с записанным звуком «Э» и получить на выходе звук «З». Однозначно можно лишь сказать, что звонкие согласные образуются с помощью вокализованного сигнала возбуждения.
В некоторую обособленную группу принято выделять сонорные согласные, которые не содержат в себе сильного турбулентного шума, т. к. при их произнесении для воздуха создается дополнительный проход (Л, Р, М, Н, Й). Однако некоторое препятствие все-таки создается (язык, язык + зубы, язык + небо), из-за этого:
— значительно ослабляются многие гармоники из начального гармонического ряда
— в целом уменьшается энергия произносимого звука
— появляются некоторые шумовые призвуки.
Звуки «М» и «Н» являются носовыми — в ротовой полости создается значительное препятствие, а носоглотка полностью открыта для прохода воздуха. Ротовая полость в таком случае является дополнительной резонансной полостью, а носовая полость становится основным излучателем звука. Звук «Р» относится к группе так называемых «дрожжащих» звуков. Сонорные звуки своим спектром достаточно сильно напоминают гласные звуки. Глядя на спектрограмму, их кратковременные появления бывает тяжело выделить, особенно при их переходе в гласные звуки. Звуки «Л», «Р», «Й» многие авторы относят к полугласным из-за возможности выделить в их составе яркие доминирующие форманты.
Стоит сказать несколько слов о призвуках и переходных звуках. Их образование связано с тем фактом, что органы артикуляции человека в слитной речи не могут взять и мгновенно изменить свое положение. Это процесс происходит плавно во времени. В фонетике принято выделять три стадии произнесения отдельного звука: экскурсия, выдержка и рекурсия. Во время экскурсии артикуляционные органы принимают начальное положение, необходимое для формирования звука. Во время выдержки произносится сам звук. Во время рекурсии органы либо приходят в состояние покоя, либо перестраиваются для начала произнесения следующего звука — рекурсия одного звука накладывается на экскурсию другого. Подобная коартикуляция пораждает множество призвуков, которые, как правило не вносятся в алфавиты, но вполне могут быть классифицированы и выделены в голосовом сигнале (к сожалению, далеко не всегда автоматически). В качестве иллюстрации можно привести спектрораммы уже измученного автором звука «П», при его отдельном произношении и в составе слога «ПЕ».

Разница между вариантами произношения звука «П» может быть видна невооруженным взглядом. В момент размыкания губ голосовой тракт уже занял позицию для произнесения смягченного «Э», что отразилось и на произношении «П». Подобные метаморфозы происходят практически со всеми согласными звуками — их положение относительно гласных звуков значительно влияет на их «внешний вид» и звучание.
Несколько фактов про гласные и согласные звуки:
1. Гласные звуки имеют гармоническую природу и четко выраженную формантную структуру. Согласные звуки имеют шумовую природу, но могут иметь ярковыраженную гармоническую составляющую (рисунок ниже, звуки «В», «Л»).
2. Гласные звуки несут в себе большее количество энергии, нежели согласные, основная её часть (1-я и 2-я форманты) лежат в диапазоне от 400 до 3000 Гц. Согласные звуки имеют значительно меньшую энергию. У большой части согласных звуков значительная часть этой энергии сосредоточена в области 2-10 КГц. Один из примеров показан ниже:
3. Гласные звуки имеют в среднем большую продолжительность, нежели согласные (100-300 мсек против 30-100 мсек, хотя конкретные точные цифры сильно зависят от языка и человека)
4. Несмотря на меньшую энергию и длительность, согласные звуки, как ни странно, несут в себе основную речевую информацию. В качестве наглядного примера можно рассмотреть неплохую задачку из Рабинера:
Восстановить фразу
«Th_y n_t_d s_gn_f_c_nt _mpr_v_m_nts _n th_ c_mp_n_s _m_g_, …» (they noted significant improvement in the company’s image, …),
против
«A__i_u_e_ _o_a___ _a_ __a_e_ e_e__ia___ __e _a_e, …» (Attitudes towards pay stayed essentially the same, …).
Речевой сигнал при слитной речи может условно считаться стационарным на отрезках от 5 до 100 миллисекунд в зависимости от особенностей диктора и произносимого звука. На более длительных интервалах анализа возрастает вероятность существенного изменения свойств сигнала, что может привести к несостоятельности оценок его усредненных параметров. Как и в любой другой области обработки сигналов, большие проблемы могут создать шумовые помехи, особенно те из них, которые имеют гармоническую природу и/или некоторые подобия формант — частотные области со сравнительно большой энергией.
В данном сжатом обзоре приведены только основные сведения о процессе речеобразования и классификации звуков речи. Даже в самом первом приближении каждый произносимый звук зависит от немалого числа параметров, индивидуальных для каждого отдельно взятого человека. Точное измерение данных физиологических параметров не всегда возможно даже современными медицинскими приборами. Если ставить себе цель получить максимально реалистичное звучание обработанного сигнала, многие из этих параметров так или иначе необходимо оценивать и единственным средством остается поиск оптимальных значений. Подобный подход почти всегда привносит артефакты в восстановленный речевой сигнал, иногда более, иногда менее слышимые. Если ещё усложнить себе жизнь и поставить задачу обработки голоса в реальном времени, то поиск этих оптимальных значений возможен только по мере обработки поступающего сигнала, так сказать, «на ходу», что также не может не отразиться на конечном звучании.
В следующей статье будет дан обзор основного инструментария, помогающего в той или иной мере решить многие задачи — кратко будут рассмотрены модели представления речевого сигнала. Также будет показано, какие параметры этих моделей можно подстраивать при ресинтезе для изменения выходного звучания.
___________
Используемая литература:
[1] И. Алдошина, Основы психоакустики, сборник статей.
[2] L.R. Rabiner, B.-H. Juang, Fundamentals of Speech Recognition
[3] L.R. Rabiner, R.W. Schafer, Digital Processing of Speech Signals
[4] Perry R. Cook, Toward the Perfect Audio Morph? Singing Voice Synthesis and Processing.
[5] В.Н. Сорокин, Синтез речи

