Самым важным процессом поисковых систем для продвижения сайта является ранжирование — процесс выстраивания элементов множества web-страниц в последовательность, определяемую убыванием рангов релевантности этих ресурсов. Для определения ранга релевантности разрабатываются алгоритмы, которые определяют, что должно влиять на позицию, при каких запросах и условиях.
С каждым годом алгоритмы ранжирования совершенствуются: добавляются новые факторы, усложняются механизмы обработки информации – и все для того, чтобы идти в ногу со временем и отвечать на запрос пользователя всегда актуальной и действительно релевантной выдачей. Как спрос определяет предложение, так и алгоритмы ранжирования стимулируют развитие сайта в направлении, востребованном посетителем.
Отсутствие механизма ранжирования привело бы к хаосу в выдаче, когда нужная информация находилась бы далеко за первой десяткой, а наличие собственного сайта не имело бы смысла, кроме как лишний штрих в визитке. Тоже касается и усложнения алгоритмов определения ранга релевантности: если бы определение происходило по индексу цитируемости и ключевым вхождениям, то мы до сих пор бы смотрели на одностраничные сайты без дизайна, не задумываясь о юзабилити.
На определение ранга релевантности влияют различные факторы ранжирования, которых очень много на сегодняшний день и которые можно объединить между собой в группы. Поисковые системы оперируют одними понятиями группировки, оптимизаторы другими. При этом влияние фактора остается неизменным в алгоритме ранжирования. Некоторые факторы могут быть равноценными, что не позволяет линейно сравнивать между собой конкурентов. Однако основные направления задать и определить можно.
В данной статье речь пойдет преимущественно о текстовой и ссылочной составляющей.
Поисковая система Яндекс является наиболее интересным исследуемым объектом в данном плане не только потому, что в ней чаще, чем в других происходят сильные изменения в алгоритме, но и потому, что данная система является первой в Рунете по работе с коммерческими или продающими запросами.
Факторы ранжирования – это те или иные признаки запроса и страницы сайта, которые важны для ранжирования и которые дают оценку странице по заданному запросу.
Можно выделить несколько групп. Первая – статические факторы, которые связаны с самой страницей, например, количество ссылок на эту страницу в интернете. Вторая группа – динамические факторы, связанные одновременно с запросом и страницей – например, присутствие на странице слов запроса, их количество и расположение. Третья группа — запросные факторы – признаки поискового запроса, например, геозависимость.
Если поисковые системы классификацию основывают на принадлежности их к запросу или странице, то seo-специалисты в основу деления ставят направления влияния факторов. Таким образом, специалист по продвижению разделяют все факторы на следующие группы:
— Факторы, оценивающие техническую составляющую сайта, которая в первую очередь влияет на возможность и качество индексации сайта;
— Факторы, оценивающие текстовую составляющую страницы и сайта, которая показывает релевантность содержимого запросу;
— Факторы, оценивающие ссылочную составляющую, как внешнюю, так и внутреннюю, как анкорную, так и трастовую, как страницы, так и всего сайта;
— Факторы, оценивающие поведенческую составляющую, нравится ли сайт посетителям, удобен ли он, отвечает требованиям пользователей;
— Факторы дополнительного назначения, такие как определение соответствия региону пользователя, задающего запрос, и сайта, определение наличия аффилиатов и другие.
Каждое направление работы с сайтом важно и нужно подходить комплексно к работе с сайтом во всех направлениях, чтобы охватить все факторы влияния на ранжирование.
В механизме ранжирования самой важной является оценка документа по релевантности содержания запросу, введенного пользователем. Для ранжирования используется текст запроса, текст документа и некоторые элементы html-разметки документа. Это основные элементы, которые использует поисковая система для составления индексных баз и для определения релевантности документа. Поэтому первое, с чем необходимо работать – это текстовая составляющая web-страницы.
Для понимания механизма оценки релевантности, важности текста и указанных ограничений требуется знать примерные модели поиска, которые представляют собой формулы и подходы, позволяющие программе поисковых систем принимать решение: какой документ считать надежным и как его ранжировать. После принятия модели коэффициенты в формулах часто приобретают физический смысл, позволяя находить свое оптимальное значение для повышения качества поиска.
Представление всего содержимого документа может быть различным – теоретико-множественные модели (булевская, нечетких множеств, расширенная булевская), алгебраические (векторная, обобщенная векторная, латентно-семантическая, нейросетевая) и вероятностные.
Примером первой модели является полнотекстовый поиск, когда документ считается найденным, если найдены все слова запроса. Однако булевское семейство моделей крайне жестко и непригодно для ранжирования. Поэтому в свое время Джойсом и Нидхэмом было предложено учитывать частотные характеристики слов, что повлекло за собой использование векторной модели.
Ранжирование в алгебраической модели основано на естественном статистическом наблюдении, что чем больше локальная частота термина в документе (TF) и больше «редкость» (т.е. обратная встречаемость в документах) термина в коллекции (IDF), тем выше вес данного документа по отношению к термину. Обозначение TF*IDF широко используется как синоним векторной модели.
Сущность метрики TF*IDF — отфильтровать значимые слова от менее значимых (предлогов, союзов и т.д.). TF (term frequency — частота слова) — отношение числа вхождения некоторого слова к общему количеству слов документа. Таким образом, оценивается важность слова в пределах отдельного документа:
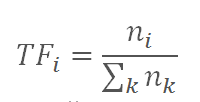
где ni – количество вхождений слова из запроса в документ,
nk – количество всех слов в документе.
IDF (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово встречается в документах коллекции, рассчитывается по-разному:
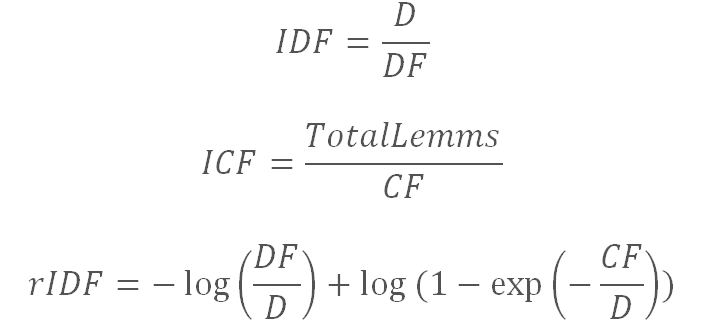
где D – число документов в коллекции,
DF – количество документов, в которых встречается лемма,
CF – число вхождений леммы в коллекцию,
TotalLemms – общее число вхождений всех лемм в коллекции.
Согласно открытым экспериментам Яндекса из всех приведенных вариантов лучший результат показал ICF.
Также существует большое множество функций нормирования и сглаживания внутри-документной частоты при вычислении контрастности TF*IDF.

Со временем приведенные формулы совершенствуются и претерпевают изменения.
В 2006-2007 годах использовалась формула подобная (2), когда были попытки добиться высокой релевантности за счет «тошноты» — переспамливания текста ключевыми словами, и это следовало наказывать.
Когда пришла необходимость бороться с «портянками» — большие тексты с ключевыми словами, стала использоваться формула (3). Затем формула еще больше усложнилась, в новом алгоритме поисковые системы используют различные тезаурусы, расширяющие запрос, определяют переспамленность текста не только большим количеством ключей, но и его шлейфом и неудобством оформления текста тегами, неграмотное написание или сочетание слов.
Релевантность в вероятностных моделях основана на оценке вероятности, окажется ли рассматриваемый документ интересным пользователю. При этом подразумевается наличие уже существующего первоначального набора релевантных документов, выбранных пользователем или полученных автоматически при каком-либо упрощенном предположении. Вероятность оказаться релевантным для каждого следующего документа рассчитывается на основании соотношения встречаемости терминов в релевантном наборе и в остальной, «нерелевантной» части коллекции.
В каждой из простейших моделей присутствует предположение о взаимонезависимости слов и условие фильтрации: документы, не содержащие слова запроса, никогда не бывают найденными. На сегодняшний день модели, используемые в ранжировании и определении релевантности, не считают слова запроса взаимонезависимыми, а, кроме того, позволяют находить документы, не содержащие ни одного слова из запроса.
Частично данную задачу решает механизм предпроцессинга запроса, который позволяет устанавливать эмпирически подобранные контекстные ограничения: на каком расстоянии искать слова из запроса, все ли слова должны присутствовать в документе, какими словами можно расширить поиск. Также происходит фактическое объединение по умолчанию контента документа и его анкор-файла в одну поисковую зону.
Механизм фильтрации по кворуму позволяет определять релевантные пассажи в документе. Релевантными считаются все полные пассажи и те неполные, сумма весов слов, которых превосходит необходимый кворум.
В 2004 году использовалась следующая формула кворума:
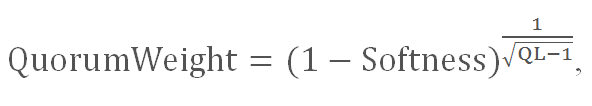
где QuorumWeight – значение кворума;
Softness – мягкость, соответствует величина от 0 до 1, в документированных записях Яндекса указывается коэффициент 0,06;
QL — длина запроса в словах.
Таким образом, основываясь на известных фактах, кворум для фразы будет иметь следующий вид, с помощью данной формулы определяются какое сочетание слов обязательно, а каким словом можно пренебречь:

где QL* — количество слов из запроса в неполном пассаже;
deg – значение степени 0.38, выведенное экспериментально
Ранжирование документа происходит на основе рассчитанного коэффициента контекстуальной схожести запросу. По факту объединяются все сведения о весе различных пассажей документа, и делается вывод о показателе релевантности документа. В одной из статей Яндекса приводится пример аддитивной модели, которая представляет собой сумму весов каждого слова, пар слов, всех слов, запроса целиком, многих слов в одном предложении и бонуса документам, похожим на помеченные экспертом, т.е. хорошие. Это показывает, что все на странице будет оценено, и доказывает, что к написанию текста нужно подходить очень ответственно.
Далее рассмотрим ссылочную составляющую.
Согласно теории поиска пользователи информационно-поисковых систем определяют ценность документа путем информационных ключей – анкора ссылки. А наличие самих ссылок увеличивает попадание посетителя на страницу. Поэтому поисковые системы используют для выделения одного документа среди кластера также принцип цитируемости.
Индекс цитирования — показатель, указывающий на значимость данной страницы и вычисляющийся на основе ссылающихся страниц на данную. Этот принцип заимствован из научных сообществ, который использовался для оценки ученых и научных организаций.
В простейшей разновидности индекса цитирования учитывается только количество ссылок на ресурс. Но он имеет ряд ограничений. Этот фактор не отражает структуру ссылок в каждой тематике, а также слабозначимые ссылки и ссылки с большой значимостью могут иметь одинаковый индекс цитируемости. Поэтому был введен термин фактор популярности (англ. Popularity Factor) или взвешенный индекс цитирования или вес ссылки, в разных поисковиках этот фактор называется по разному: PageRank в Google, вИЦ в Яндексе. Сами ссылки участвуют в статическом передачи веса, показывая популярность ресурса, и анкорном – по заданным ключам. Также существует тематический индекс цитирования (тИЦ), учитывающий также тематику ссылающихся на ресурс сайтов.
Первоначально, до того как для продвижения сайта стали работать с ссылочной составляющей, индекс цитирования реально отражал популярность соответствующего ресурса в интернете. Как-то в одной из статей технический директор Яндекса Илья Сегалович упомянул, что введение ссылочного поиска и статической ссылочной популярности помогло поисковым системам справиться с примитивным текстовым спамом, который полностью разрушал традиционные статистические алгоритмы информационного поиска, полученные в свое время для контролируемых коллекций.
В 1998 году появилась статья с описанием принципов алгоритма PageRank, используемого в Google. Взвешенный индекс цитирования, как и другие ссылочные факторы ранжирования, рассчитывается из ссылочного графа.
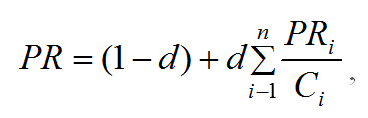
PR — PageRank рассматриваемой страницы,
d — коэффициент затухания (означает вероятность того, что пользователь, зашедший на страницу, перейдет по одной из ссылок, содержащейся на этой странице, а не прекратит путешествие по сети),
PRi — PageRank i-й страницы, ссылающейся на страницу,
Ci — общее число ссылок на i-й странице.
Основная идея заключается в том, что страница передает свой вес распределяя его на все исходящие ссылки, поэтому чем больше ссылок на странице доноре, тем меньший вес каждой достанется. Другая не менее важная идея заключается в понимании принципа цитируемости – это оценка вероятности перехода посетителя по одной из ссылки, а следовательно, вероятность популярности самой страницы сайта, на который ставятся ссылки. Соответственно, чем больше качественных ссылок, тем вероятность популярности ресурса выше.
На сегодняшний день ссылки часто наносят вред качеству поиска, поэтому поисковые системы стали вести борьбу с ссылочной накруткой – размещение Seo-ссылок на сторонних сайтах на коммерческой основе и предназначенные для манипуляции алгоритмами ранжирования. Они принимают все меры, чтобы сайты, продающие ссылки, потеряли способность влиять таким способом на ранжирование, а покупка ссылок с сайтов не могла бы привести к повышению ранга сайта-покупателя.
Алгоритмы, применяемые в современных поисковых системах для оценки ссылочной составляющей, претерпели большие изменения, но качество и количество ссылок сохранили свое прямое влияние при выделении страницы среди кластера копий. Чем авторитетней и тематически схожа с вашим ресурсом страница-донор, тем больший вес будет передан сайту, тем выше будет его позиция в поиске.
Автор статьи: Неелова Н.В. (к.т.н., руководитель отдела ПП Ingate).

