Содержание
Файл robots.txt предоставляет важную информацию для поисковых роботов, которые сканируют интернет. Перед тем как пройтись по страницам вашего сайта, поисковые роботы проверяют данный файл.
Это позволят им с большей эффективностью сканировать сайт, так как вы помогаете роботам сразу приступать к индексации действительно важной информации на вашем сайте (это при условии, что вы правильно настроили robots.txt).
Но, как директивы в robots.txt, так и инструкция noindex в мета-теге robots являются лишь рекомендацией для роботов, поэтому они не гарантируют что закрытые страницы не будут проиндексированы и не будут добавлены в индекс.
Если вам нужно действительно закрыть часть сайта от индексации, то, например, можно дополнительно воспользоваться закрытие директорий паролем.
Основной синтаксис
User-Agent: робот для которого будут применяться следующие правила (например, «Googlebot»)
Disallow: страницы, к которым вы хотите закрыть доступ (можно указать большой список таких директив с каждой новой строки)
Каждая группа User-Agent / Disallow должны быть разделены пустой строкой. Но, не пустые строки не должны существовать в рамках группы (между User-Agent и последней директивой Disallow).
Символ хэш (#) может быть использован для комментариев в файле robots.txt: для текущей строки всё что после # будет игнорироваться. Данные комментарий может быть использован как для всей строки, так в конце строки после директив.
Каталоги и имена файлов чувствительны к регистру: «catalog», «Catalog» и «CATALOG» – это всё разные директории для поисковых систем.
Host: применяется для указание Яндексу основного зеркала сайта. Поэтому, если вы хотите склеить 2 сайта и делаете постраничный 301 редирект, то для файла robots.txt (на дублирующем сайте) НЕ надо делать редирект, чтобы Яндекс мог видеть данную директиву именно на сайте, который необходимо склеить.
Crawl-delay: можно ограничить скорость обхода вашего сайта, так как если у вашего сайта очень большая посещаемость, то, нагрузка на сервер от различных поисковых роботов может приводить к дополнительным проблемам.
Регулярные выражения: для более гибкой настройки своих директив вы можете использовать 2 символа
- * (звездочка) – означает любую последовательность символов
- $ (знак доллара) – обозначает конец строки
Основные примеры использования robots.txt
Запрет на индексацию всего сайта
User-agent: *
Disallow: /
Эту инструкцию важно использовать, когда вы разрабатываете новый сайт и выкладываете доступ к нему, например, через поддомен.
Очень часто разработчики забывают таким образом закрыть от индексации сайт и получаем сразу полную копию сайта в индексе поисковых систем. Если это всё-таки произошло, то надо сделать постраничный 301 редирект на ваш основной домен.
А такая конструкция ПОЗВОЛЯЕТ индексировать весь сайт:
User-agent: *
Disallow:
Запрет на индексацию определённой папки
User-agent: Googlebot
Disallow: /no-index/
Запрет на посещение страницы для определенного робота
User-agent: Googlebot
Disallow: /no-index/this-page.html
Запрет на индексацию файлов определенного типа
User-agent: *
Disallow: /*.pdf$
Разрешить определенному поисковому роботу посещать определенную страницу
User-agent: *
Disallow: /no-bots/block-all-bots-except-rogerbot-page.html
User-agent: Yandex
Allow: /no-bots/block-all-bots-except-Yandex-page.html
Ссылка на Sitemap
User-agent: *
Disallow:
Sitemap: http://www.example.com/none-standard-location/sitemap.xml
Нюансы с использованием данной директивы: если у вас на сайте постоянно добавляется уникальный контент, то
- лучше НЕ добавлять в robots.txt ссылку на вашу карту сайта,
- саму карту сайта сделать с НЕСТАНДАРТНЫМ названием sitemap.xml (например, my-new-sitemap.xml и после этого добавить эту ссылку через «вебмастерсы» поисковых систем),
так как, очень много недобросовестных вебмастеров парсят с чужих сайтов контент и используют для своих проектов.
Что лучше использовать robots.txt или noindex?
Если вы хотите, чтобы страница не попала в индекс, то лучше использовать noindex в мета-теге robots. Для этого на странице в секции <head> необходимо добавить следующий метатег:
<meta name=”robots” content=”noindex, follow”>.
Это позволит вам
- убрать из индекса страницу при следующем посещение поискового робота (и не надо будет делать в ручном режиме удаление данной страницы, через вебмастерс)
- позволит вам передать ссылочный вес страницы
Через robots.txt лучше всего закрывать от индексации:
- админку сайта
- результаты поиска по сайту
- страницы регистрации/авторизации/восстановление пароля
Как и чем проверить файл robots.txt?
После того, как вы окончательно сформировали файл robots.txt необходимо проверить его на ошибки. Для этого можно воспользоваться инструментами проверки от поисковых систем:
Google Вебмастерс: войти в аккаунт с подтверждённым в нём текущим сайтом, перейти на Сканирование -> Инструмент проверки файла robots.txt.

В данном инструменте вы можете:
- сразу увидеть все свои ошибки и возможные проблемы,
- прямо в этом инструменте провести все правки и сразу проверить на ошибки, чтобы потом уже перенести готовый файл себе на сайт,
- проверить правильно ли вы закрыли все не нужные для индексации страницы и открыты ли все нужные страницы.
Яндекс Вебмастер: чтобы воспользоваться данным инструментом просто перейдите по этой ссылке http://webmaster.yandex.ru/robots.xml.
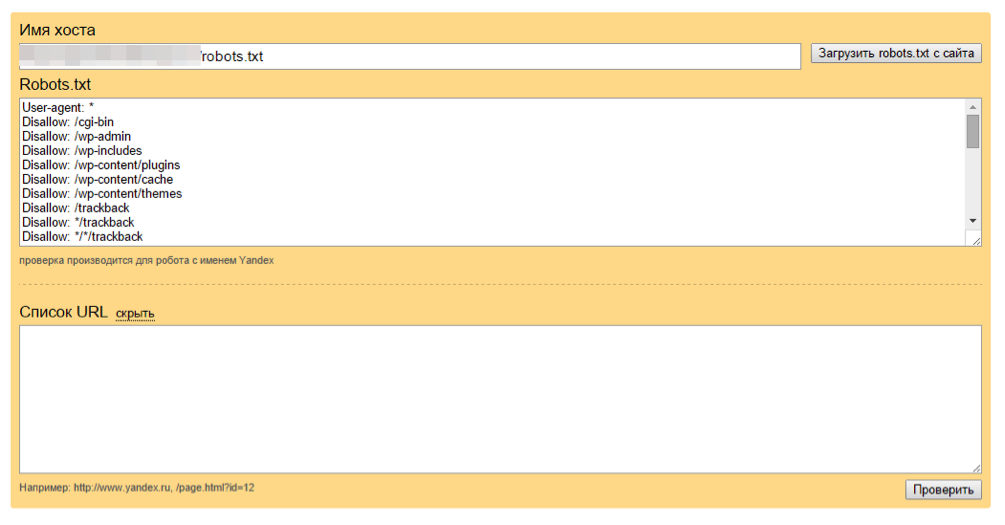
Этот инструмент почти аналогичный предыдущему с тем небольшим отличием, что:
- тут можно не авторизоваться и нет необходимости в подтверждении прав на сайт, а поэтому, можно сразу приступать к проверке вашего файла robots.txt,
- для проверки сразу можно задать список страниц, а не вбивать их по одному,
- точно убедиться, что Яндекс правильно понял ваши инструкции.
В заключение
Создание и настройка robots.txt является в списке первых пунктов по внутренней оптимизации сайта и началом поискового продвижения.
Важно его настроить грамотно, чтобы нужные страницы и разделы были доступны к индексации поисковых систем. А не нужные были закрыты.
Но главное помнить, что robots.txt не гарантирует того, что страницы не будут проиндексированы. Как когда-то сказала наша коллега Анастасия Пареха:
Robots.txt — как презерватив, вроде защищает, но вероятность всегда есть)
