Содержание

Сегодня на airbnb вышел очень интересный пост о том, как они делают A/B-тесты. Мне показалось, что перевод данной статьи будет интересен Хаброжителям, так как многие создают собственные проекты, и методы анализа airbnb как максимум могут оказаться полезными, как минимум позволят задуматься о том, что неплохо бы тестировать метрики вашего продукта.
Airbnb — это онлайн площадка, на которой встречаются предложения людей по аренде домов и запросы людей, которые ищут, где им остановиться в поездке. Мы проводим контролируемые эксперименты, которые позволяют нам принимать решения при разработке продукта, начиная от дизайна и заканчивая созданием алгоритмов. Это очень важно при формировании удобства для пользователя.
Принципы при проведения экспериментов простые, но часто приводят к обнаружению неожиданных подводных камней. Иногда эксперименты останавливаются слишком быстро. Другие, которые не работают на обычной торговой площадке, почему-то начинают работать на специализированной типа airbnb. Мы надеемся, что наши результаты помогут кому-то избежать подводных камней и это позволит вам делать лучше дизайн, лучше управлять, и проводить более эффективные эксперименты в ваших проектах.
Зачем эксперименты?
Эксперименты — простой способ сделать понятный интерфейс. Это часто неожиданно сложно — рассказать то, что ты делаешь простым языком, и посмотрите что происходит на первой иллюстрации: 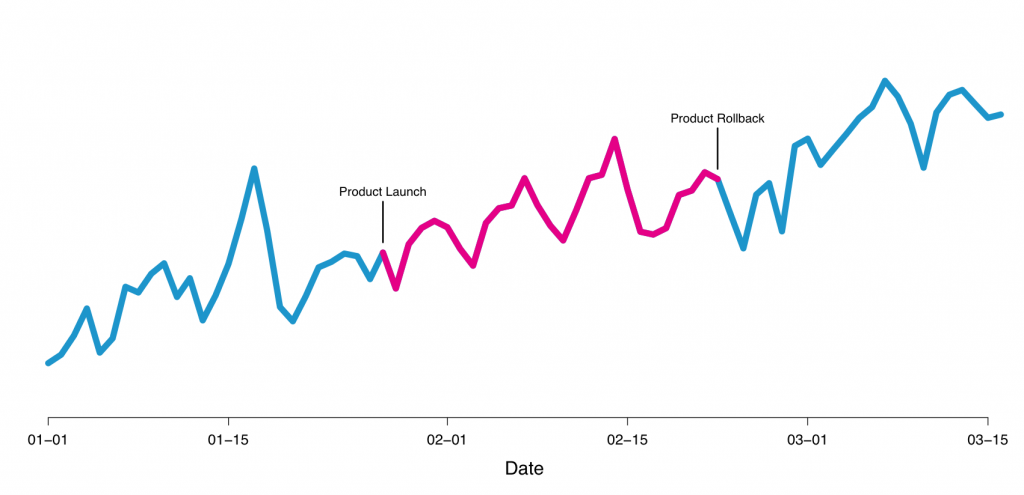
Иллюстрация 1
Внешний мир сильно меняет продукт. Пользователи могут вести себя по-разному в зависимости от дня недели, времени года, погоды (относительно нашего сервиса, или другого туристического проекта), или узнают о сервисе через рекламу, или органически. Контролируемые эксперименты изолируют влияние на изменение продукта пока контролируются вышеупомянутые внешние факторы. На иллюстрации 2, вы можете увидеть пример новой фичи, которую мы тестировали, но от которой отказались. Мы думали, что внедрим новый способ выбора цены, который будет приятен пользователю, но получили уменьшение конверсии, поэтому отказались от нее. 
Рисунок 2 — пример новой фичи, которую мы тестировали, но отказались
Когда ты тестируешь одиночные изменения типа этого, то методология называется обычно A/B-тестирование или сплит-тесты. Этот пост не содержит базовой информации о применении A/B-тестов. Есть несколько больших компаний, где вы можете найти подобные сервисы. Например, Gertrude, Etsy’s Feature, and Facebook’s PlanOut,
Тестирование в AirBnb
В AirBnB мы создали собственный A/B-фреймворк для тестирования, в котором возможно запускать эксперименты. Есть несколько специальных фич в нашем бизнесе, которые тестируются более тщательно, чем обычные изменения цвета кнопки и именно поэтому мы сделали собственный фреймворк.
Во-первых, пользователи могут просматривать сайт, когда они авторизованы или не авторизованы, что делает тестирование достаточно сложным. Люди часто переключаются между устройствами(между веб и мобильным) в промежутке между бронированием. Также бронирование может занять несколько дней, и поэтому мы должны ждать результаты. В итоге заявки и быстрые отклики владельцев жилья — факторы, которые мы также хотим контролировать.
Существует несколько вариаций при бронировании. Сначала, посетитель пользуется поиском. Затем связывается с арендодателем. Затем арендодатель подтверждает заявку и затем гость бронирует место. В дополнение у нас есть вариации, которые также могут приводить к бронированию другими путями — гость сразу бронирует без связи с хостером или может сделать запрос на бронь сразу же. Эти четыре визуально показаны на рисунке 3. Мы объединили процесс прохождения этих шагов и общую конверсию между поиском и бронированием, которые являются нашими основными показателями. 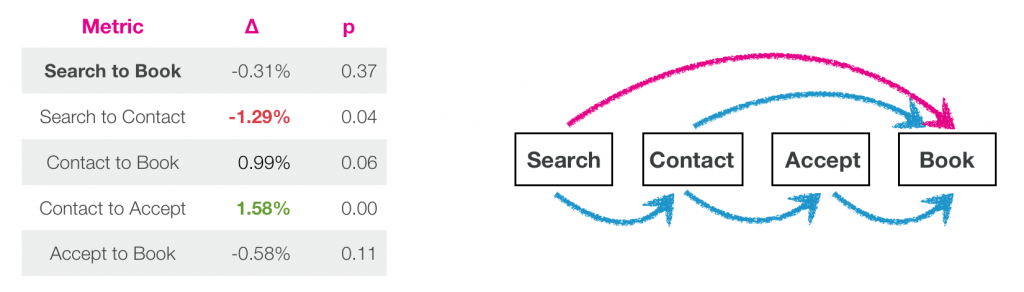
Рисунок 3 — пример экспериментов
Как долго стоит вести эксперименты
Самый большой источник путаницы в онлайн-экспериментах заключается в том, что ты не знаешь сколько времени ты должен вести эксперимент, чтобы получить результат. Проблема заключается в том, что когда вы наивно используете p-value, как критерий остановки эксперимента и полагаетесь на эти результаты. Если же вы продолжаете мониторить тест и результаты P-value, то вы скорее всего увидите эффект. Другая общая ошибка — останавливать эксперимент слишком рано, до того, как эффект становится видным.
Здесь пример наших экспериментов, которые мы запускали. Мы тестировали максимальное значение цены, которое участвует в фильтре на поисковой странице, изменяя его от $300 до $1000: 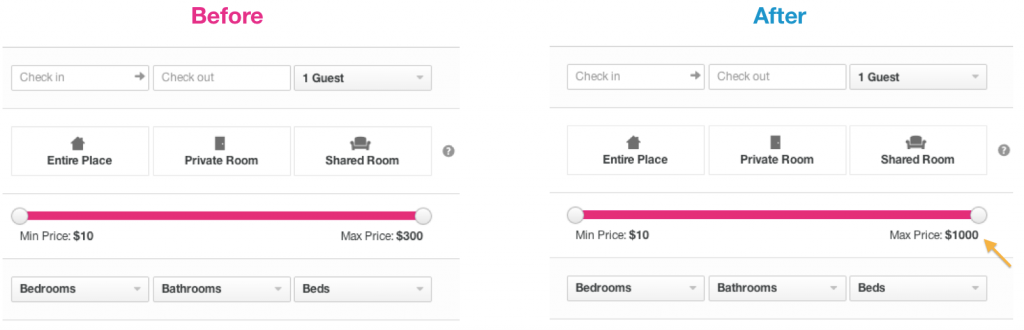
Иллюстрация 4 — Пример тестирование цены в фильтре
В иллюстрации 5 мы показываем тест по времени. Верхний график показывает treatment effect, а снизу график, показывающий зависимость p-value от времени. Как вы видите, P-value превышает 0.05 после 7 дней, в котором значение эффекта 4%. Если мы остановили бы эксперимент там, то не получили значительных результатов, которые получили при бронировании. Мы продолжили эксперимент и дошли до момента, когда эксперимент стал нейтральным. Окончательный эффект был практически равен нулевому p-значению, сигнализируя, что остался только шум. 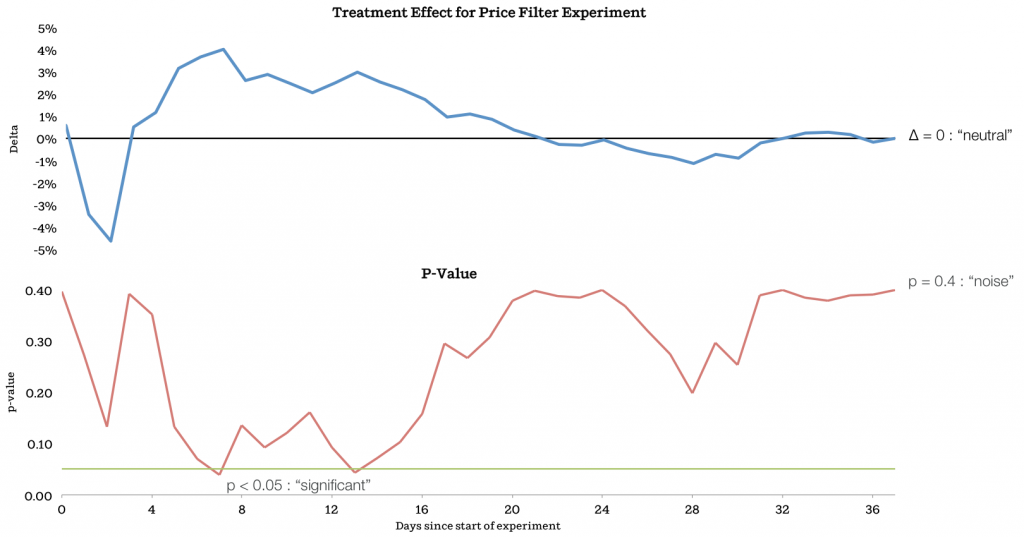
Иллюстрация 5 — результат зависимости фильтра эксперимента от времени
Почему мы не остановили эксперимент, когда p-значение было равно 0.05? Оказывается, что в обычных системах такого не происходит. Для этого есть несколько причин. Пользователи часто достаточно долго принимают решение о заказе и ранние заказы слишком сильно влияют на начало эксперимента.
Чтобы получить правильный результат вы должны выполнять статистический тест каждый раз, когда вы вычисляете р-значение, и чем больше вы это делаете, тем больше вероятность того, чтобы получить эффект.
Обращаем внимание, что люди, которые близко работали с сайтом могли заметить, что во время запуска теста для максимального значения цены effect был нейтральным. Мы обнаружили, что определенные пользователи, которые бронируют достаточно дорогие дома, сильно не влияют на эту метрику, так как заказывают быстро.
Как долго эксперимент должен быть запущен, чтобы предотвратить негативные изменения? Лучшая практика заключается в том, чтобы запускать эксперименты с минимальными эффектами, которые позволят вычислить размер эффекта.
Существует момент, когда эксперимент приводит к успеху или к неудаче, даже когда еще не вышло время. В случае фильтрации цены пример, который мы показали увеличение было первым достижением, но график не явно это показал, потому что кривые не сошлись. Мы нашли этот момент очень полезным, когда результаты могут быть не совсем стабильными. Это важно для исследования и разработки важных метрик, поэтому скорее рассматривая одиночный результат с p-значением.
Мы можем использовать этот пример для еще большего понимания того, когда именно нужно останавливать эксперимент. Это может быть полезно, если вы делаете много экпериментов в одно и то же время. Интуиция подсказывает, что вы должны быть недоверчивы к любым первым результатам. Поэтому, когда результаты слишком низкие вначале — это ничего не означает. 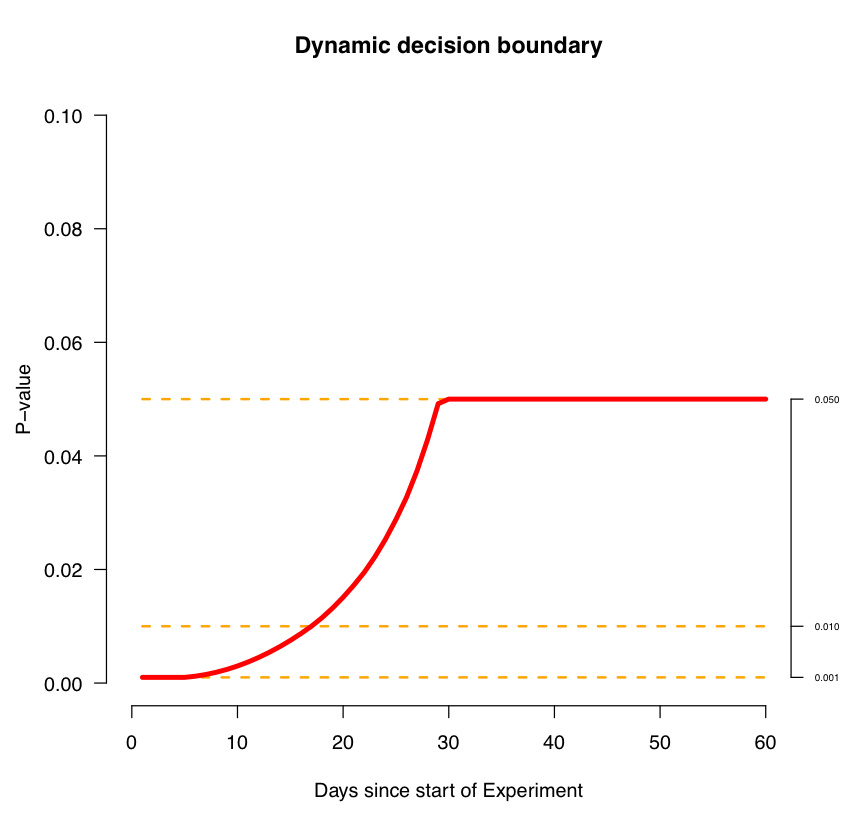
Иллюстрация 6
Следует заметить, что эта кривая частично параметр нашей системы, который мы используем в экспериментах. Для вашего проекта будут свои значения.
Вторая западня — анализ результатов в общем контексте. В основном практика оценки успеха эксперимента базируется на одиночной метрике. Однако из-за этого вы можете упустить массу ценной информации.
Приведем пример. Последний год мы провели за редизайном нашей поисковой страницы. Поиск это фундаментальный компонент Airbnb. Это главный интерфейс нашего продукта и самый прямой путь увлечь пользователей нашим сайтом. Поэтому так важно сделать ее правильной. На иллюстрации 7 вы можете увидеть страницу до и после изменений. Новый дизайн содержит больший размер картинок большую карту, на которой показано, где расположены объекты. Вы можете прочитать об изменени дизайна в другом посте. 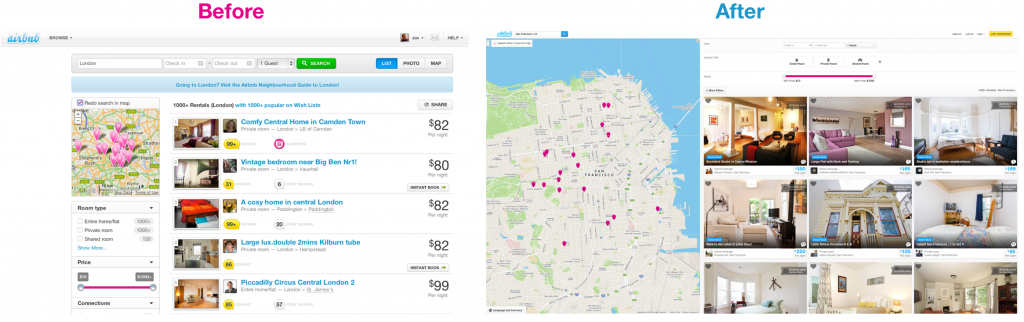
Иллюстрация 7
Много работы мы провели за этим проектом и мы думали и пытались сделать дизайн как можно лучше, после чего захотели оценить наш дизайн при помощи эксперимента. Большим соблазном было запустить дизайн и показать его сразу всем, чтобы не упустить маркетинговую возможность. Однако, собравшись с духом, сначала мы протестировали новый дизайн.
После ожидания достаточного количества времени по методологии описанной выше, мы получили результаты. Изменения глобальных метрик были крошечными и p-значение сигнализировало о нулевом эффекте. Однако мы решили посмотреть глубже на результаты, чтобы понять все причины и следствия. Мы нашли, что новый дизайн был лучше в большинстве случаях, за исключением Internet Explorer. Затем мы решили, что новый дизайн ломает возможность кликать в старых версиях этого браузера, что значительно повлияло на результаты. Когда мы поправили это, IE стал показывать близкие результаты к другим браузерам, показывая повышение в 2%. 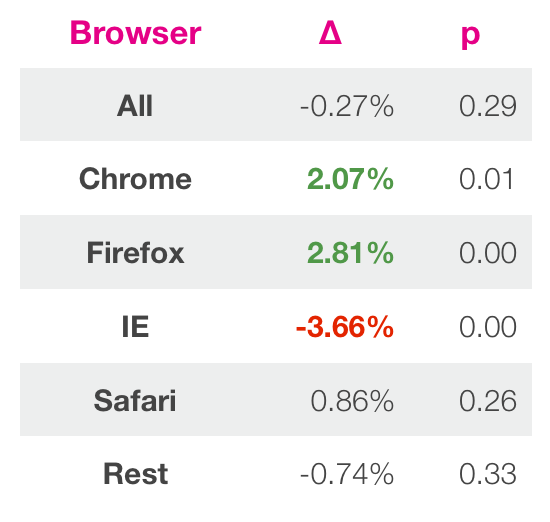
Иллюстрация 8
Это научило нас более внимательно относиться нас к тестирование в IE. Этот пример хорошо иллюстрирует, что нужно разбираться в контексте тестирования. Вы можете получить низкие результаты по множеству причин похожими на версию браузера, страны и типа пользователя. Обычные фреймворки могут просто не отразить некоторую специфику, которую вы можете обнаружить, исследуя вручную. Вы можете множество раз прогонять одни и те же тесты, но в конечно итоге обнаружить меленькую вещь, которая приведет к значительному эффекту. Причиной этого может быть то, что вы запускаете сразу множество тестов, полагая, что они все работают независимо, но это не так. Одним из способов достичь этого — понизить p-значение до уровня, при которой вы решите, что эффект реален. Подробнее об этом можно почитать здесь.
Система должна работать
Третий и заключительный подводный камень на сегодня заключается в предположении, что система работает. Вы можете думать, что ваша система работает и эксперименты проходят. Однако, система может не отражать реальности. Это может случиться, если фреймворк поврежден, или вы используете его неправильно. Один из способов оценить систему и ваше токование ей заключается в формулировании гипотез и их проверки. 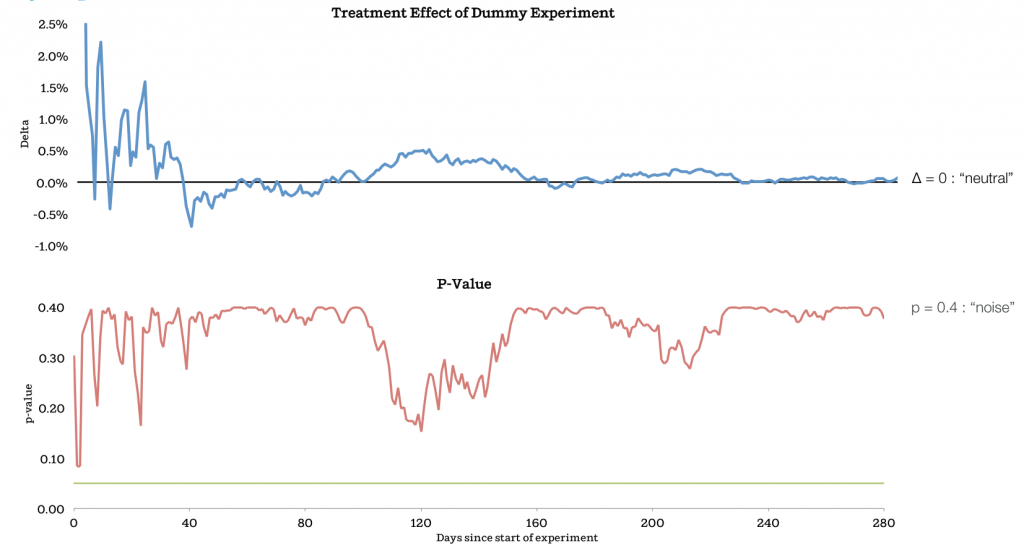
Иллюстрация 9
Другой способ взглянуть на результаты, которые могут показаться слишком хорошими, чтобы быть правдой. Когда вы изучаете результаты, похожие на эти, то хорошей практикой является сначала их внимательно изучить до того, как посчитать правдой.
Самый простой пример, когда treatment равен контрольному значению. Это называется A/A или фиктивные эксперименты. В идеальном мире система вернет нейтральные результаты. Но что возвращает ваша система? Мы запускали множество экспериментов похожих на эти (иллюстрация 9) и сравним предположения с результатами. В одном случае мы запустили фиктивные эксперименты.
Вы можете видеть, что в экспериментах где контролируемые и treatments группы с похожими размерами, результаты выглядят так.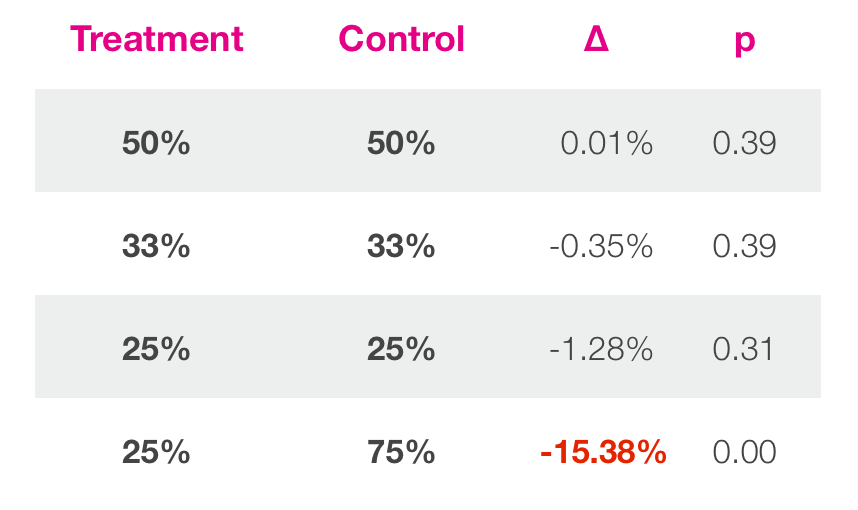
Иллюстрация 10
Заключение
Контролируемые эксперименты — хороший способ для принятия решения при разработке продукта. Будем надеяться, что уроки, показанные в этом посте, помогут предотвратить некоторые ошибки, допускаемые при A/B-тестировании.
Во-первых, лучший способ определить как долго нужно продолжать эксперимент, чтобы делать выводы. Если система дает тебе ранние результаты, ты можешь начать делать нестрогую оценку или тренды должны сойтись. Нужно быть консервативным в данном сценарии.
Важно смотреть результаты в их контексте. Распределите их по осмысленным группам и попробуйте глубже их понять. В основном, эксперименты могут быть хорошей дискуссией о том, как улучшить продукт, скорее чем начать агрессивно оптимизировать продукт. Оптимизация не не возможна, но часто руководствоваться авантюристическим порывом не стоит. Фокусируясь на продукте вы можете обсудить и принять правильное решение.
В окончании нужно быть на ты с вашей системой отчетов. Если что-то не выглядит правильным или кажется слишком хорошим, чтобы быть правдой, то изучите это. Самый простой способ сделать это, запустить фиктивные тесты, потому что любые знания о том, как система ведет себя будут полезные для понимания результатов. В AirBnb мы нашли достаточное количество ошибок благодаря этому.
[ Источник ]
P.S. Уже буквально через неделю в Кремниевой долине состоится конференция SVOD, на которую еще есть возможность попасть ;)

