Содержание
Мы живем во времена, когда кажется, что все просто и все есть. Нужно сделать масштабируемый проект — используем MongoDB, нужна очередь — вот RabbitMQ, нужно поднять функционал поиска — раз плюнуть: ставим Sphinx, Solr, ElasticSearch (нужное подчеркнуть).
Но здесь лишь доля правды: — при определенном везении можно поставить нужный сервер и все зашевелится. Загвоздка с поиском состоит в том, что пользователи уже порядком привыкли к высокой планке, которую задают «большие ребята», а тот поиск, что поднимется у вас «из коробки», будет явно недотягивать. И если очередь или базу данных вы можете добить железом прежде, чем будете оптимизировать, то поиск железом не добьешь.
Существую толстые книжки про настройки полнотекстового поиска, однако их мало кто читает. Сегодня я хотел бы на пальцах поговорить о том, что нужно учесть, когда вы делаете префиксный поиск с выводом результатов по мере набора слова или фразы.
Мы посмотрим, как с помощью нашего проекта http://indexisto.com сделан поиск на сайте http://maximonline.ru и сравним его с тем, что есть на других сайтах.
Для начала несколько примеров. Возьмем запрос «Битва за Лос Анджелес» и представим, что его напишут неправильно «Лос Анжелес биттва». Как видно, пользователь не знает точно, как пишется имя города, и забыл, как звучит название фильма, а также у него дрогнула рука в конце на слове «битва».
Выберем достойные проекты рунета, в которых есть префиксный поиск, и попробуем поискать там наш запрос:
| Проект | Правильный запрос | Неправильный запрос |
|---|---|---|
| afisha.ru | 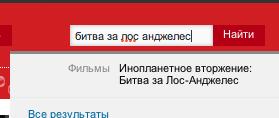 все ОК |
 Не найдено |
| ivi.ru |  все ОК |
 Не найдено |
| vk.com | 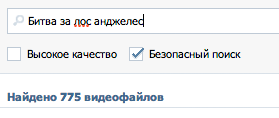 все ОК |
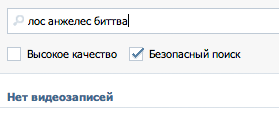 Не найдено |
| maximonline.ru | 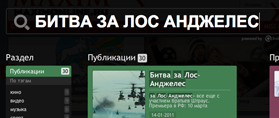 все ОК |
 все ОК |
Как видно из нашего небольшого исследования, ситуация далека от идеальной. Вот типичные проблемы
- Не работает перестановка слов
- Наблюдаются «скачки». То есть по мере набора искомый фильм то появляется в результатах, то пропадает.
- Отсутствие нечеткого поиска
- Не у всех есть морфология
Поехали настраивать
В статье речь будет идти о сервере ElasticSearch, однако эти же подходы можно использовать и при настройке SOLR, так как в итоге все высокоуровневые запросы все равно мапятся на запросы более низкоруровневой библиотеки поиска Lucene. Также не принципиально, делаете ли вы префиксный поиск с помощью ngram токенизаторов или с помощью префиксных запросов (довольно тяжеловесных, так как они мапятся на fuzzy-запросы).
Индексация
При индексации текст проходит через токенизатор и ряд фильтров (морфология, синонимы…). Оригинальное слово в итоге может быть заменено, приведено к нормальной форме или вообще выкинуто. Через какие бы фильтры вы ни прогоняли ваши токены, сохраняйте оригинальное слово в той же позиции, что и измененное/замененное. Что может случиться, если не сохранить оригинальное слово, показанно на картинке:
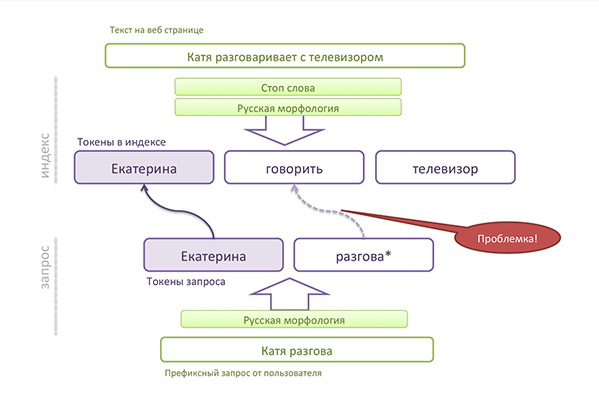
Как видите, фильтр морфологии меняет слово (приводит к нормальной форме). В обычном поиске это работает хорошо, так как слово из запроса, который ввел пользователь, тоже будет приведено к нормальной форме. Но что делать, пока пользователь ввел только половину слова (префиксный поиск)? Сохраняем оригинальный токен в индексе!
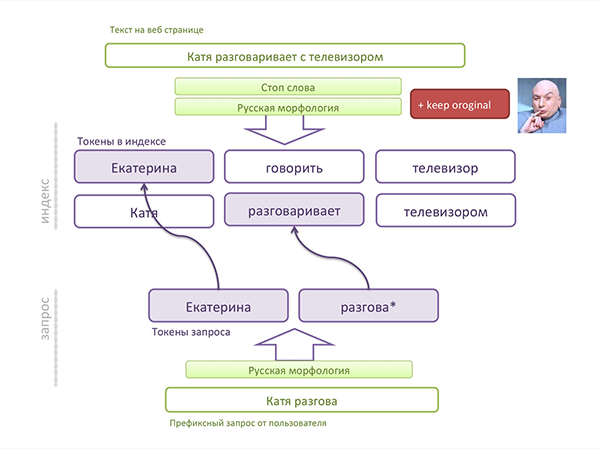
У нас, кстати, возникли проблемы в стандартных плагинах Lucene, и мы сделали свои, которые лучше работают с позициями токенов в документе и сохранением оригинального слова. О том, какие проблемы вас могут поджидать, можно почитать, например, здесь:Lucene’s TokenStreams are actually graphs!
Анализаторы запроса
Не используйте анализаторы, которые могут вам «подчистить» запрос, например, фильтр стоп-слов, который удаляет междометия и частицы. Вот пример:
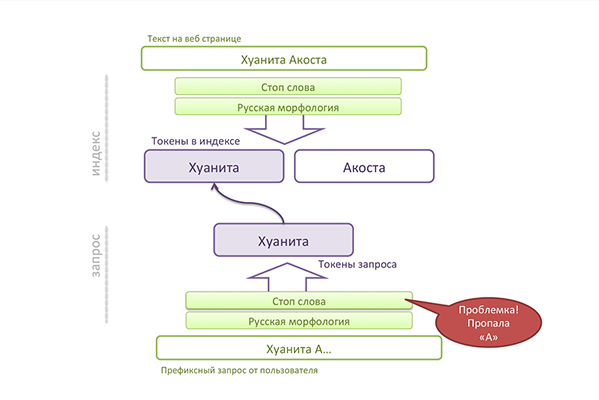
Как видите, «а» это стоп-слово, и анализатор запроса ее удалил. На практике это означает, что будет «скачок», то есть человек набрал «Хаунита А» и видит документ по запросу Хуанита (без А). Если у нас много Хуанит в выдаче, то нет никакой гарантии, что нужная нам будет сверху.
Для того, чтобы это побороть, убираем фильтр стоп-слов из запроса:
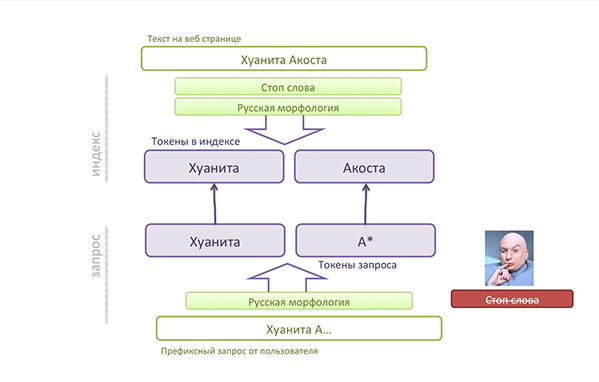
Запрос
Не пытайтесь сделать все сразу одним путанным гигантским запросом. Разбейте задачу на подзадачи. Существуют булевы и dismax-запросы, которые помогут вам склеить результаты работы нескольких мелких запросов в один. Используйте boost в небольших запросах, чтобы, к примеру, увеличить вес точного совпадения в title страницы по сравнению с совпадением в body страницы. Примерно вот так:
{
"query":{
"bool" : {
"should" : [
{
"custom_boost_factor": {
"query":{
"match":{
....
}
},
"boost_factor": 100
}
},
{
"custom_boost_factor": {
"query":{
"match":{
....
}
}
},
"boost_factor": 10
}
},
.....
]
}
}
}
Точное совпадение фразы в заголовке статьи
Итак, наш поисковый запрос состоит из кучки маленьких запросов с разными boost-факторами. Boost-фактор — это множитель релевантности, который применяется, когда базовая текстовая релевантность уже посчитана.
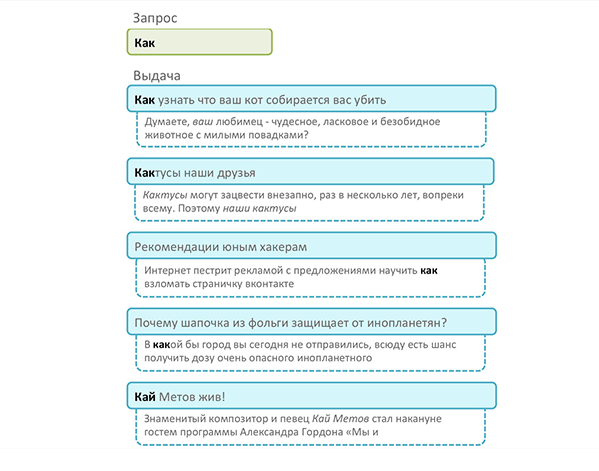
Сначала у нас идет поиск на точное совпадение фразы в заголовке статьи (или title страницы). Точное совпадение означает, что мы не используем префикс. Например, запрос«КАК» выведет первыми статьи «Как правильно…», а не статью «Выращиваем кактус». Документы, найденные по такому запросу, получают буст, к примеру, 10000.
Префиксное совпадение фразы в заголовке статьи
Далее идет запрос на префиксное совпадние фарзы. Точные совпадения слова «КАК» нам уже нашел первый запрос, теперь время поискать «кактусы». Эти документы будут идти ниже точных совпадений за счет меньшего буста.
Мы также здесь используем параметр slop, который говорит, что слова в фразе могут отстоять друг от друга на несколько позиций вперед или назад. Многие забывают про этот параметр, а по умолчанию префиксный поиск ищет только вперед.
Вот какая выдача получается на текущий момент:

Первыми идут точные совпадения, вторыми — префиксные.
Совпадения в теле статьи — полное и префиксное
Совпадения в заголовке мы нашли и сделали им приличный буст. Время перейти к самому телу статьи. В первую очередь мы опять ищем точное совпадение, и с меньшим boost-фактором префиксные совпадения.
Таким образом, совпадения в заголовке будут первыми в выдаче, а совпадения в теле статьи — ниже. Встает вопрос: не отдать ли подобную сортировку на откуп текстовой релевантности? Ведь стандартные алгоритмы учитывают длину текста, в котором найдено совпадение: чем короче текст, тем выше релевантность. Однако практика показала, что при префиксном поиске в теле статьи будет очень много совпадений. Представьте, вы набрали 1-2 буквы, а в теле статьи будет уже 200-300 совпадений, и, несмотря на длину текста, они перебьют релевантность совпадений в заголовке.
Нечеткие совпадения в заголовке или теле статьи
Последним (за счет буста) идет нечеткий поиск. Нечеткий поиск прощает некоторые опечатки в поисковом запросе, введенном пользователем. Внутри запроса используетсяLevenshtein distance. Нечеткий запрос имеет несколько настроек, которые выступают в качестве параметров к алгоритму, а также есть возможность указать минимальное необходимое совпадение префикса.
"custom_boost_factor": {
"query":{
"multi_match":{
"query":"${q}",
"fuzziness":0.005,
"prefix_length" : 2,
"operator":"and",
"max_expansions":999,
"fields":[
"article_name",
"article_body"
]
}
},
"boost_factor": 1
}
}
Совпадения, найденные нечетким поиском, идут в самом низу за счет минимального boost-фактора.
Что в итоге
На картинке видно, как выстроились наши результаты в зависимости от совпадений:
- в заголовке точные
- в заголовке по префиксу
- в теле статьи точные
- в теле статьи по префиксу
- в заголовке и теле статьи нечеткие (с опечатками)
Бонус-трек для тех, кто осилил статью
Мы собираем всю статистику поисковых запросов, клики по результатам выдачи, поиски без переходов, поиски с пустым результатом.
Интересно, что на maximonline.ru поиск довольно востребованный функционал, а 90% поисковых запросов это имена девушек. Здесь можно получить очень интересные данные :)
Итак, самые искомые читателями Maxim девушки в обратном порядке! Данные за ноябрь 2013.
5. Анна Семенович (телеведущая)

4. Вера Брежнева (певица)

3. Анна Хилькевич (актриса)

2. Мария Горбань (актриса)

1. Екатерина Волкова (актриса)


