Содержание
Для меня всегда было некоей магией то, как Getpocket, Readability и Вконтакте парсят ссылки на страницы и предлагают готовые статьи к просмотру без рекламы, сайдбаров и меню. При этом они практически никогда не ошибаются. А недавно подобная задача назрела и в нашем проекте, и я решил копнуть поглубже. Сразу скажу, что это «белый» парсинг, вебмастеры сами добровольно пользуются нашим сервисом.
В идеальном мире вся информация на страницах должна быть семантически размечена. Умные люди придумали много полезных штук типа Microdata, OpenGraph, тэги Article, Nav …etc, но полагаться на сознательность вебмастеров в плане семантики я бы не спешил. Достаточно самим посмотреть код страниц популярных сайтов. Open Graph кстати самый востребованный формат, всем хочется красиво выглядеть в соц. сетях
Вычленение заголовка статьи и картинки остается за рамками моего поста, так как заголовок обычно берется из title или og, а картинка если она не берется из og:image – это отдельный рассказ.
Переходим к самому интересному – вычленению тела статьи.
Оказывается, есть вполне себе научные paper’ы посвященные этой проблеме (в том числе от сотрудников Гугла). Есть даже соревнование CleanEval с набором тестовых страниц из которых надо извлечь данные, и алгоритмы соревнуются в том кто сделает это точнее.
Выделяются следующие подходы:
- Извлечение данных пользуясь только html документом (DOM и текстовый уровень). Именно эту технику мы обсудим ниже
- Извлечение данных используя отрендеренный документ с помощью computer vision. Это очень точный алгоритм, но и самый сложный и прожорливый. Посмотреть как работает можно например вот здесь: www.diffbot.com/ (проект ребят из Стэнфорда).
- Извлечение данных на уровне сайта целиком, сравнивая однотипные страницы и находя различия между ними (различающиеся блоки это по сути и есть нужный контент). Этим занимаются большие поисковики.
Нас сейчас интересуют подходы к извлечению статьи имея на руках лишь один html документ. Параллельно мы можем решить проблему определения страниц со списками статей с пагинаций. В данной статье мы говорим о методах и подходах, а не окончательном алгоритме.
Парсить будем страницу http://habrahabr.ru/post/198982/
Список кандидатов на то чтобы стать статьей
Берем все элементы разметки структуры страницы (для простоты — div) и текст который в них содержится (если он есть). Наша задача получить плоский список DIV элемент –> текст в нем
Например блок меню на Хабре:
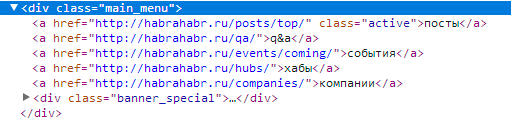
Дает нам элемент содержащий текст «посты q&a события хабы компании»
При наличии вложенных div элементов, их содержание отбрасывается. Дочерние div будут обработаны в свою очередь. Пример:

Мы получим два элемента, в одном текст ©habrahabr.ru, а во втором Служба поддержки Мобильная версия
Мы предполагаем что в 21 веке элементы которые семантически предназначены для разметки структуры (div), не используют для разметки параграфов в тексте, и это на топ 100 новостных сайтов действительно так.
В итоге из дерева у нас получается плоский набор:
И так, у нас есть набор в котором надо классифицировать статью. Далее, с помощью различных довольно простых алгоритмов каждому элементу мы будем понижать или повышать коэффициент вероятности наличия в нем статьи.
DOM дерево мы не выкидываем, оно нам понадобится в алгоритмах.
Находим повторяющиеся паттерны.
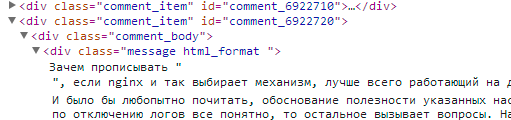
Во всех элементах DOM дерева мы находим элементы с повторяющимися паттернами в атрибутах (class, id..). Например если приглядится к комментариям:
Становится понятно, что такое повторяющийся паттерн:
- Одинаковый набор классов у элементов
- Одинаковая текстовая подстрока в id
Все эти элементы и их «детишек» мы пессимизируем, то есть ставим некоторый понижающий коэффициент в зависимости от количества найденных повторений.
Когда я говорю про «детишек» я имею ввиду, что все вложенные элементы (включая те которые попали в наш набор для классификации) получат пессимизацию. Вот, например, элемент с текстом комментария тоже попадает под раздачу:
Соотношение ссылок и обычного текста в элементе.
Идея понятна – в меню и в колонках мы видим сплошные ссылки, что явно не похоже на статью. Пробегаемся по элементам из нашего набора и каждому проставляем коффициент.
Например, текст в элементах в блоке Фрилансим (он у нас уже получили минус за повторяющийся класс), получают минус в догонку за некрасивое соотношение ссылок к тексту равное единице. Понятно, что чем меньше этот коэффициент, тем больше текст похож на осмысленную статью:
Соотношение элементов разметки текста к тексту
Чем больше в блоке всякой разметки (списки, переносы, span…), тем меньше шанс, что это статья. Например, реклама вероятно уважаемой SEO компании, не очень похожа на статью, так как целиком представляет собой список. Чем ниже значение соотношения разметки к тексту тем лучше.

Количество точек (предложений) в тексте.
Здесь мы уже почти заползли на территорию численной лингвистики. Дело в том, что в заголовках и меню точки практически не ставятся. А вот в теле статьи их много.
Если какие-то меню и списки новых материалов на сайте еще пролезли через предыдущие фильтры, то можно добить подсчетом точек. Не очень-то их много в блоке лучшее:
Чем больше точек, тем лучше, и мы повышаем шансы данному элементу на получения гордого звания статьи
Количество блоков с текстом примерно одинаковой длины
Много блоков с текстом примерно одной длины это плохой признак, особенно если текст короткий. Мы такие блоки пессимизируем. Идея хорошо сработает на подобной верстке:
В примере не Хабр, так как данный алгоритм лучше работает на более строгих сетках. На комментариях на Хабре сработает к примеру не очень хорошо.
Длина текста в элементе
Здесь прямая зависимость – чем длиннее текст в элементе, тем больше шансов на то, что это статья.
Причем вклад этого параметра в итоговую оценку элемента очень существенен. 90% случаев парсинга статьи можно решить одним этим методом. Все предыдущие изыскания поднимут этот шанс до 95%, но при этом скушают львиную долю процессорного времени.
Однако представьте: комментарий размером с саму статью. Если просто определять статью по длине текста случится конфуз. Но есть высокий шанс, что предыдущие алгоритмы немного подрежут крылья нашему комментатору-графоману, так как элемент будут пессимизирован за повторяющийся паттерн в id или классе.
Или еще один случай — увесистое выпадающее меню сделанное с применением <ul><li>. Вроде текста много, но мы то видим что там все в разметке и ссылках.
Итоговый результат
Зная базовые подходы, мы можем реализовать алгоритмы и подобрать вручную или машинным обучением необходимые веса/коэфициенты. В итоге мы получаем список кандидатов, каждый из которых получил свои плюсы и минусы:

Выводы
Современные подходы и алгоритмы позволяют по одному только тексту страницы добиться качества распознания статьи около 95%.
Однако есть ярко выраженные случаи когда алгоритм не сработает. К примеру есть статья на 300 слов, к ней один комментарий на 350 слов, и внизу сайта в футере написан SEO текст на 400 слов.
Повышение качества достигается учетом «оформления» текста (смотрим еще и CSS), рендериногом страницы (тяжелый алгоритм) или сравнением нескольких однотипных страниц с сайта.
Некоторые использованные материалы
Christian Kohlschütter, Peter Fankhauser, Wolfgang Nejdl
Boilerplate Detection using Shallow Text Features
J. Gibson, B. Wellner, and S. Lubar.
Adaptive web-page content identication.
Hung-Yu Kao, Jan-Ming Ho
WISDOM: Web Intrapage Informative Structure
Mining Based on Document Object Model
Частично реализованный наш алгоритм можно посмотреть на проекте:
http://indexisto.com
Готовые алгоритмы для вашего языка можно найти по запросам «boilerplate algorithm», «readability algorithm»
