Обосновывая необходимость управления сниппетами (аннотации сайтов в выдаче), важно понимать, что трафик получаемый продвигаемым сайтом из поисковой выдачи, равен произведению числа показов на CTR. Сам же показатель CTR – это функция позиции и кликабельности сниппета. Соответственно, решая задачу по повышению кликабельности, владелец ресурса параллельно решает задачу по увеличению целевого трафика на сайт.
Факторы положительно влияющие на кликабельность можно грубо разделить на 4 группы: читабельность; соответствие запросу; размер и «заметность» сниппета в результатах выдачи.
Основные варианты путей для влияния также сводятся к 4 направлениям:
- Использовать документированные возможности по форматам от поисковых систем.
- Конструировать и пытаться влиять на нужные фрагменты.
- Использовать недокументированные возможности по форматам поисковых систем.
- Предоставить поисковым системам возможность «самим все решать».
В статье основное внимание уделено исследованию влияния на вероятность включения алгоритмом в сниппет интересующего текстового фрагмента, а также различным интересным приемам, которые явно не описаны поисковыми системами.
Чтобы влиять на решение поисковой системы по выбору нужного фрагмента, необходимо выделить факторы, которые учитывают при этом поисковики.
Ниже перечислено несколько публикаций Яндекса, откуда можно почерпнуть перечень нужных факторов:
1. Так, из статьи «Алгоритмы контекстно-зависимого аннотирования Яндекса на РОМИП-2008» были выделены следующие факторы:
- Полное вхождение.
- Точное вхождение.
- Близость к началу предложения.
- Близость к началу содержания страницы.
- Наличие в предложении слов с высоким IDF.
- Размер фрагмента примерно 150 символов.

2. Из статьи «Влияние на сниппеты используя поведение пользователей»:
- Полное вхождение.
- Точное вхождение.
- Близость к началу предложения.
- Максимизация IDF на фрагмент и на слово из фрагмента.
- Близость к началу содержания страницы.
- Отсутствие избыточного кол-ва пунктуации / кол-во слов с заглавной буквы.

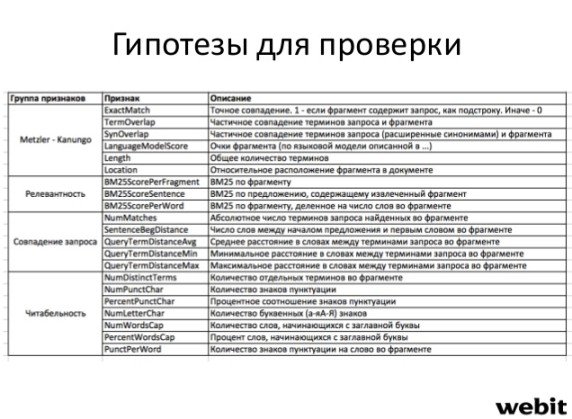
После дополнения перечня собственными гипотезами был получен итоговый список факторов для проверки:
- Полное вхождение.
- Точное вхождение.
- Близость к началу предложения.
- Максимизация IDF на фрагмент и на слово из фрагмента.
- Близость к началу содержания страницы.
- Размер фрагмента примерно 150 символов.
- Отсутствие избыточного кол-ва пунктуации / кол-во слов с заглавной буквы.
- Вес тега meta description.
- Влияние подсветок (топонимы, синонимы и остальное).
В следующей части статьи рассмотрены результаты проверки гипотез на тестовых страницах, которые специально создавались для экспериментов. Данные, полученные в ходе исследования на тестовой коллекции документов, проверялись статистикой на реальных запросах и сайтах (всего несколько десятков тысяч).
Сравнивая полное/точное вхождение с неполным, ожидаемо получили что:
- Для Яндекса везде выигрывает полное вхождение.
- В случае наличия в descrition полного, а в документе неполного вхождения – Яндекс берёт descrition.
Сравнивая группу начало предложения/документа с IDF, удалось выявить, что:
- Для Яндекса почти 80% случаев выигрывает первая группа.
- Сравнение внутри первой группы требует отдельной выборки.
При сравнении близости точного вхождения к началу документа с близостью точного вхождения к началу предложения проверки на тестовой коллекции показали, что в ¾ случаев выигрывает начало документа.
Для проверки вывода про сильную роль такого фактора как «начало документа» на реальной коллекции был проведен замер расположения фрагмента, который берется в сниппет по отношению ко всему документу. Чисто рассчитать без учета меню и с учетом других факторов было достаточно проблематично, но даже грубый подсчет в целом подтвердил гипотезу.
При поиске ответа на вопрос, каким должен быть идеальный размер сниппета в Яндексе, было обнаружено, что разброс по возможной длине достаточно большой и хорошо коррелирует с длиной самого запроса.

Следующей задачей было исследовать роль тега meta Description для Яндекс и Google. Для этого создали тестовые страницы, где разместили 2 похожих предложения: одно — в тексте документа, а другое — в meta description:

Причем проверка на выборке из десятков тысяч запросов также это подтвердила:

По итогам получаем первичную рекомендацию относительно того, какими признаками должен обладать фрагмент, чтобы попасть в сниппет:
Для Яндекса:
- Выигрывает полное вхождение.
- Имеет значение как близость точного вхождения к началу документа, так и к началу предложения.
- Размер фрагмента зависит от длины запросов (от 120-160 символов до 180-200).
- О descrition можно не сильно заботиться.
Для Google:
- Имеет смысл максимальное использование descrition.
- Важно создавать «красивые» сниппеты. Сделать это можно, к примеру, при помощи такого инструмента.
На следующей стадии эксперимента в тестовой коллекции сравнивалось наличие слов из подсветки (это, например, «Москва», «купить», «цена», «отзывы» и пр.) с их отсутствием в сниппете.

В отношении реальной коллекции ситуация была следующей:

На основе анализа слов из подсветки в выдаче Яндекса на 20 000 запросов были сделаны следующие наблюдения:
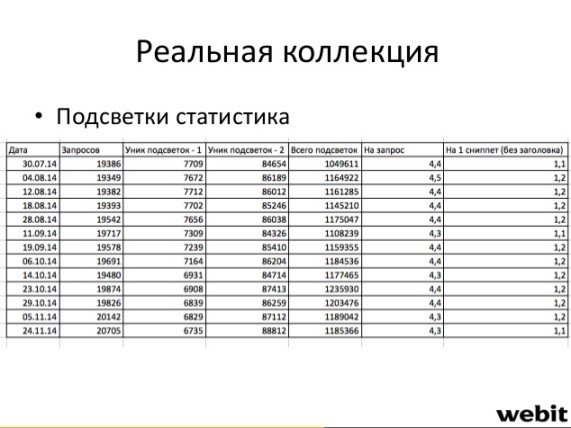
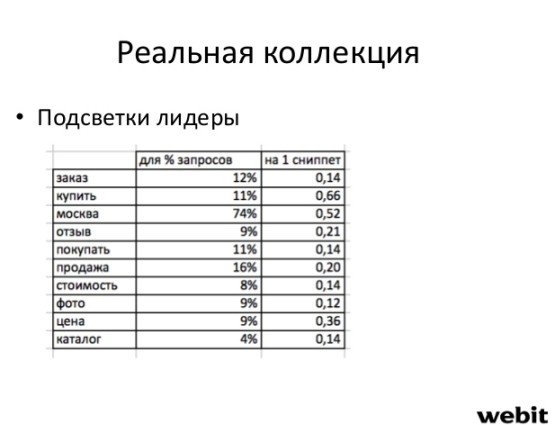
Отдельное внимание было обращено на слова из подсветки, которые относятся к так называемым синонимам. Это слова или фразы, которые Яндекс считает синонимами по отношению к исходному запросу. Так, оператор «nosyn» убирает подсветки связанные с синонимами и, по всей видимости, исключает их из ранжирования. Было выяснено, что порядка 30% подсветок приходится на синонимы.

Итоги проделанной работы позволили сформулировать окончательные рекомендации для того, чтобы максимально влиять на интересующий сниппет:

Интересные примеры сниппетов в Яндексе могут быть, к примеру, такими:


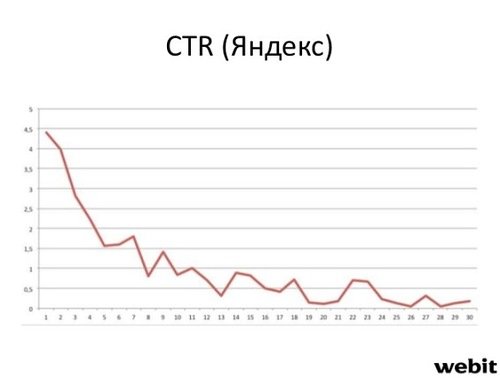
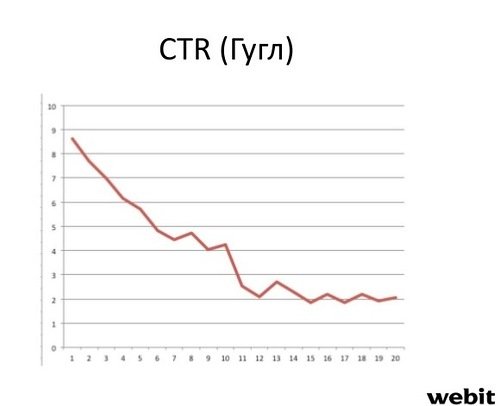
Результаты целесообразности влияния на сниппеты проверялись на основе наблюдений за ростом показателя CTR. Причем эксперименты производились на практических кейсах. Для этого было получено распределение среднего CTR на десятках тысяч запросов для Яндекс и Google. Далее исследователи выясняли значимо ли превышает CTR сниппетов, с которыми они работали, средний CTR для данной позиции. Ожидаемо оказалось, что в большинстве случаев сниппеты, где шла целенаправленная работа по методике, показали лучшие результаты.
Что касается быстророботной примеси, то по итогам наблюдений автора статьи, а также согласно публикациям компании Яндекс на данную тему, можно прийти к следующим выводам:

Выступление Станислава Поломаря (Webit) состоялось на втором дне конференции «Интернет и Бизнес. Россия» в рамках секции «Исследования алгоритмов поисковых машин». В ходе секции участники обсудили вопросы обнаружения фильтров и санкций на сайте, вывода сайта из-под фильтров. Поделились своими открытиями по поводу последних изменений поисковой выдачи. Модератором стал Сергей Людкевич, независимый консультант.
Полная версия презентации доклада Станислава Поломаря на тему: «Алгоритмы аннотирования, влияние на сниппеты и примеси в выдаче» доступна на Slideshare.
