Содержание
О чем собственно речь
Как-то раз одним поздним декабрьским вечером завершился сбор материала для хабра-статьи, посвященной SAT. Материала оказалось слишком много и передо мной встал выбор: разделить статью на две части или собрать весь материал вместе в одной статье. Выбор был сделан в пользу разделения на части. К моему удивлению, вторая часть получила значительно меньше внимания, чем первая — фактически её прочитали в два раза меньше человек. Время шло, и я стал замечать, что это происходило не только с моими статьями, но и со многими другими статьями в нескольких частях. Тогда у меня возник вопрос, а верно ли в общем, что вторая часть получает меньше внимания (просмотров, плюсов, и записей избранного)?

(сделано на основе хабра-статьи Как лгать с помощью статистики)
Структура статьи
В итоге мне пришла следующая идея: собрать пары статей — первая-вторая часть и посмотреть, есть ли существенная разница в основных параметрах между статьями. А так же оценить, как эти параметры меняются для статей в нескольких (более двух) частях.
Данные
Как и в предыдущей статье, все данные, код и скрипты для визуализации доступны для скачивания в github. Вы можете повторить все эксперименты, а так же собрать и проверить все исходные данные — используя код ипримеры из предыдущей статьи. Прежде всего это нужно, чтобы обеспечить прозрачность и повторяемость экспериментов, а так же дать некоторую начальную точку для тех, кто захочет провести собственные исследования хабра-данных.
Собрать данные о статьях в нескольких частях — задача далеко не самая простая, но мы можем собрать достаточное количество статей используя пару простых идей. Рассмотрим датасет all.csv с хабра-статьями из прошлой статьи 
Большой опыт чтения хабра подсказал мне, что информацию о том, что имеет несколько частей, стоит искать в заголовке (title в табличке). Если мы пройдемся по всем заголовкам на предмет наличия ключевого слова часть, то мы можем собрать неплохой набор кандидатов. Простой скрипт filter.py для предварительной фильтрации статей выдал внушительный, но не огромный список статей кандидатов сгруппированный по авторам. Проведя разбор кандидатов, были сформированы два датасета series1.csv и series2.csv, содержащий первые и вторые части соответственно:
Каждый из датасетов содержит по 180 записей.
Сравниваем части
Рассмотрим разницу между первыми и вторыми частями по следующим показателям: просмотры, рейтинг и записи в избранное. На каждом из графиков ниже синяя точка означает первую часть статьи, а красная точка означает вторую часть. Две части одной статьи отображаются на одинаковой x-координате. Если разница в измерении просмотров, рейтинга или избранного положительная между первой и второй части положительная, то сегмент между ними синий, а если отрицательная, то красный. Визуально, чем больше синих линий мы видим, тем чаще первая часть оказывается лучше, согласно измеренным параметрам. Статьи на графиках отсортированы по увеличению параметра первой статьи.
На первом графике мы видим явное преобладание первых частей над вторыми по просмотрам, только в 10% случаев вторая часть оказывается лучше первой. Но большинство этих случаев демонстрирует несущественную разницу в просмотрах, среди всех записей только в двух случаях мы видим существенное преобладание второй части над первой. Медиана количества просмотров порядка 20к для первых частей и 10к для вторых.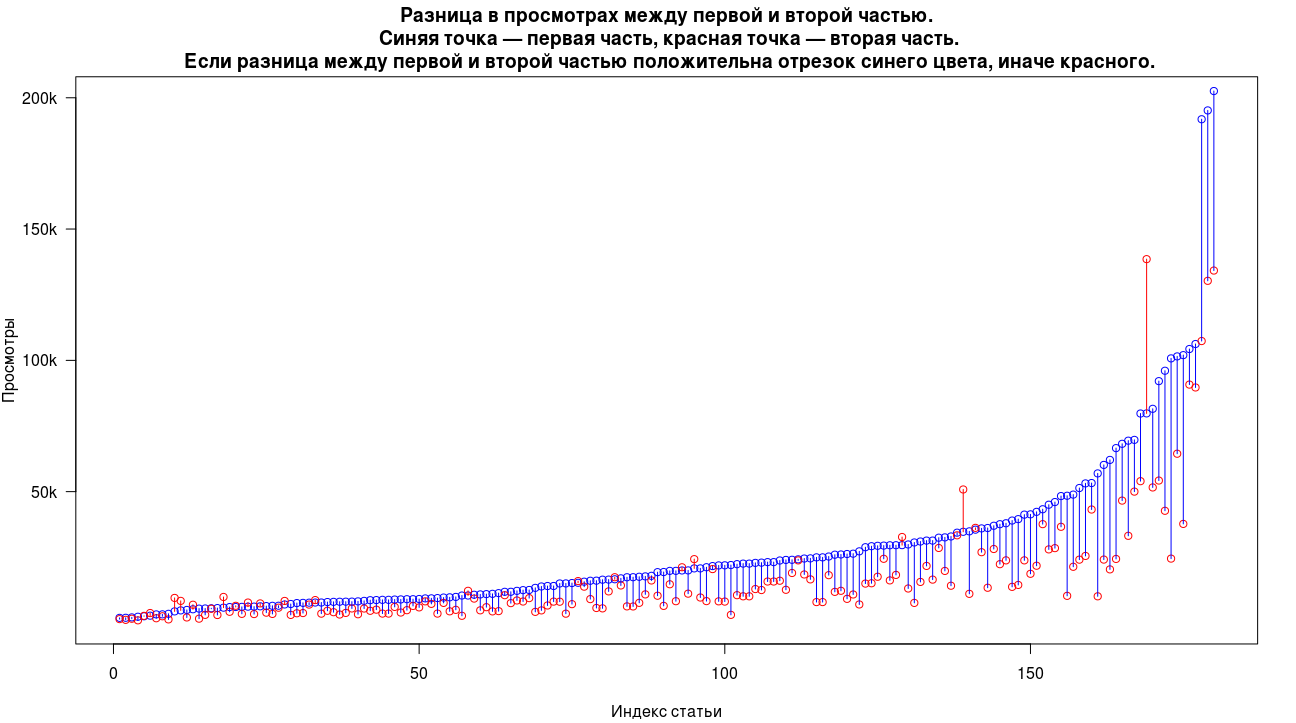
В целом мы видим схожую картину по записям в избранное, только в 14% случаев вторая часть набирает больше записей в избранное, существенное преобладание есть только в одном случае. Медиана записей в избранное 137 для первых частей и 82 для вторых.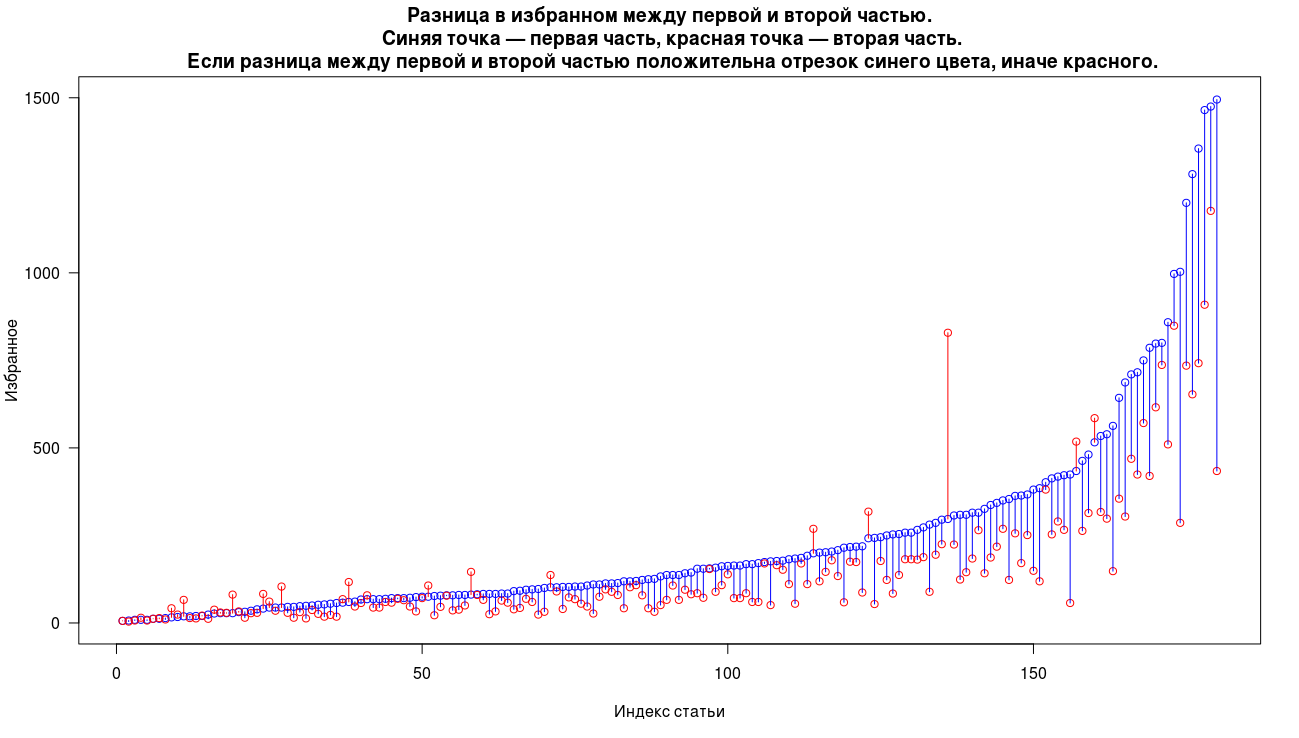
В случае с рейтингом вторые части доминируют над первыми чаще в 22% процентов случаев. Существенное преобладание, как и в случае с просмотрами возникает только в двух случаях. Медиана рейтинга для первых частей 25 и 17 для вторых.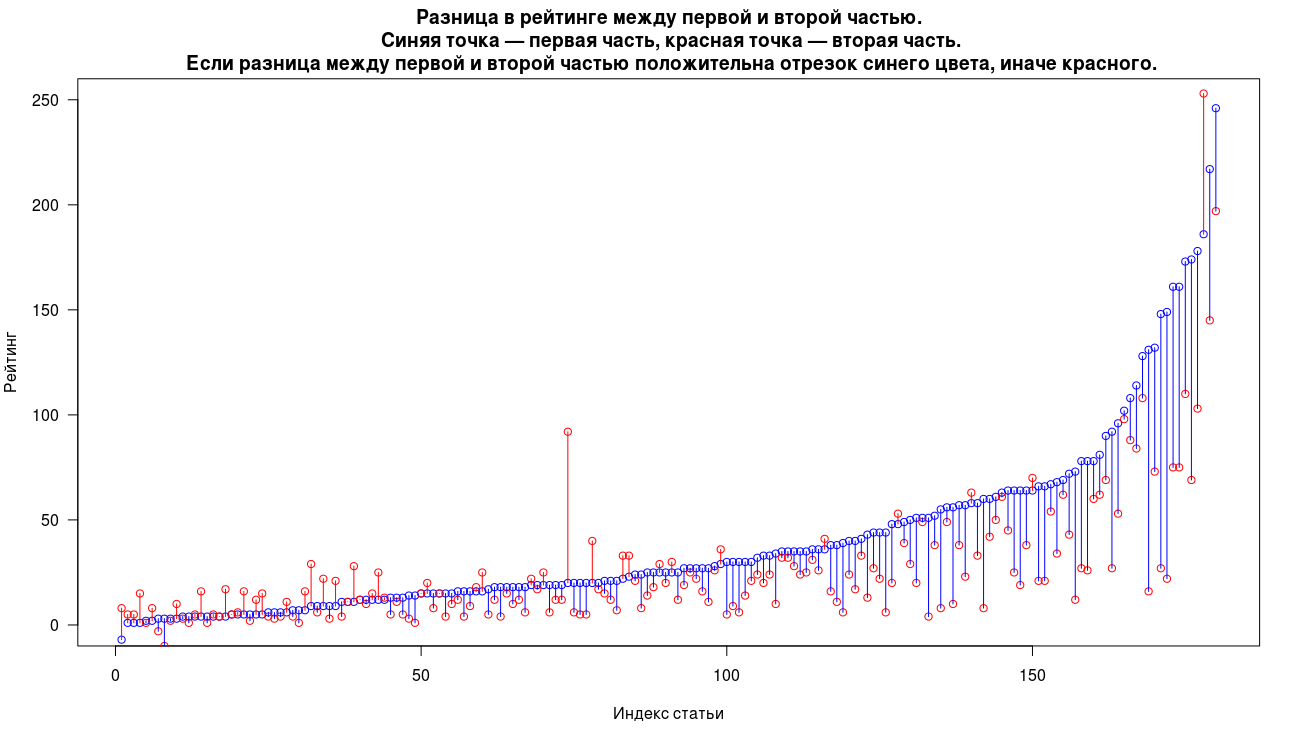
(графики получены с помощью скрипта difference.R)
Если кому-то интересно, то существенное преобладание второй частью над первой происходит вот в этих статьях:
Как я писал Pacman’a, и что из этого получилось. Часть 1
Как я писал Pacman’a, и что из этого получилось. Часть 2
и самая большая разница в показателях в статье:
Часть 1. Unboxing VisuMax — фемто-лазера для коррекции зрения
Часть 2. Сколько мегабит/с можно пропустить через зрительный нерв и какое разрешение у сетчатки? Немного теории
Серии статей
Еще интереснее рассмотреть длинные цепочки статей. Из общего числа кандидатов, были отобраны цепочки статей из 5 и более частей — их можно найти в датасете series_long.csv.
Данные имеют следующий формат:
Собранные данные представляют очень ограниченную по размерам выборку, поэтому сложно сделать однозначные выводы, но мы можем по крайней мере оценить общий характер изменений. Приведем в качестве примера и мотивации три самые длинные цепочки из статей за собранный период.
Прежде всего мы видим, что первая часть набрала существенно больше просмотров, чем остальные части. Для второй и третьей части падение имеет фактор порядка двух, потом падение замедляется и просмотры стабилизируются.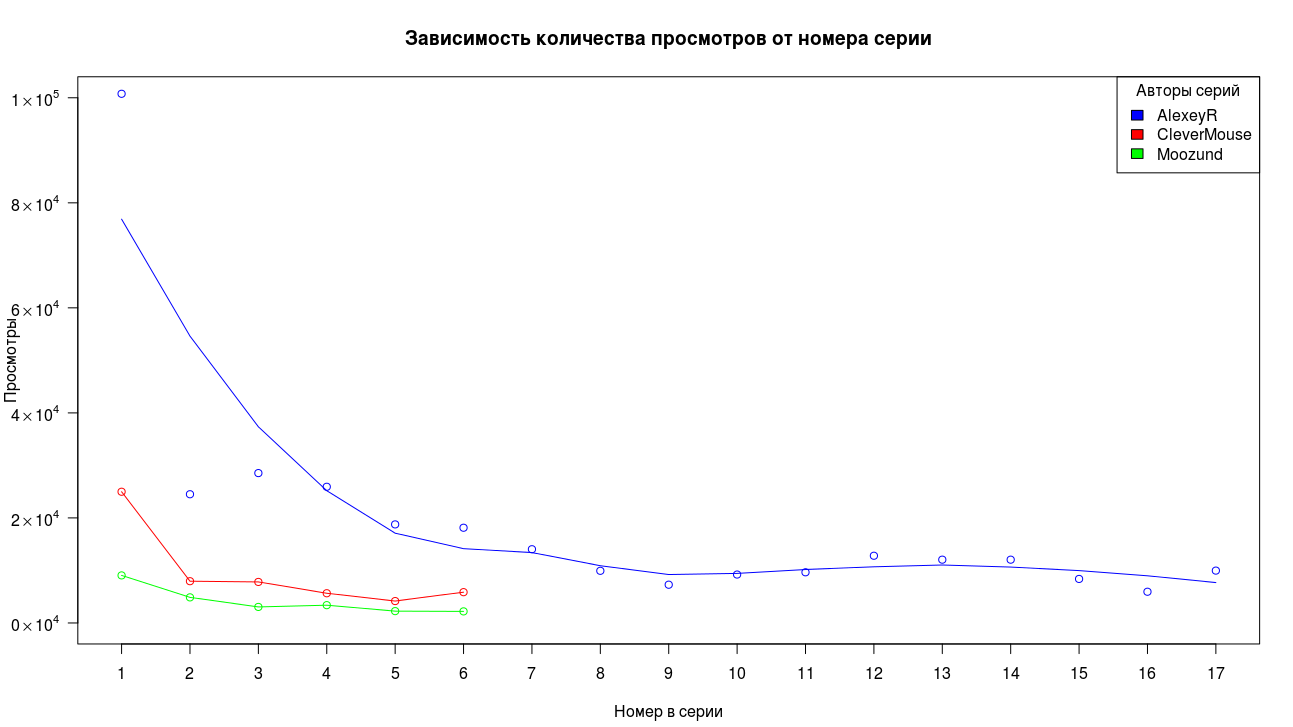
Мы видим в целом схожую картину по записям в избранное, высокое значение первой точки, резкое падение и стабилизацию хвоста.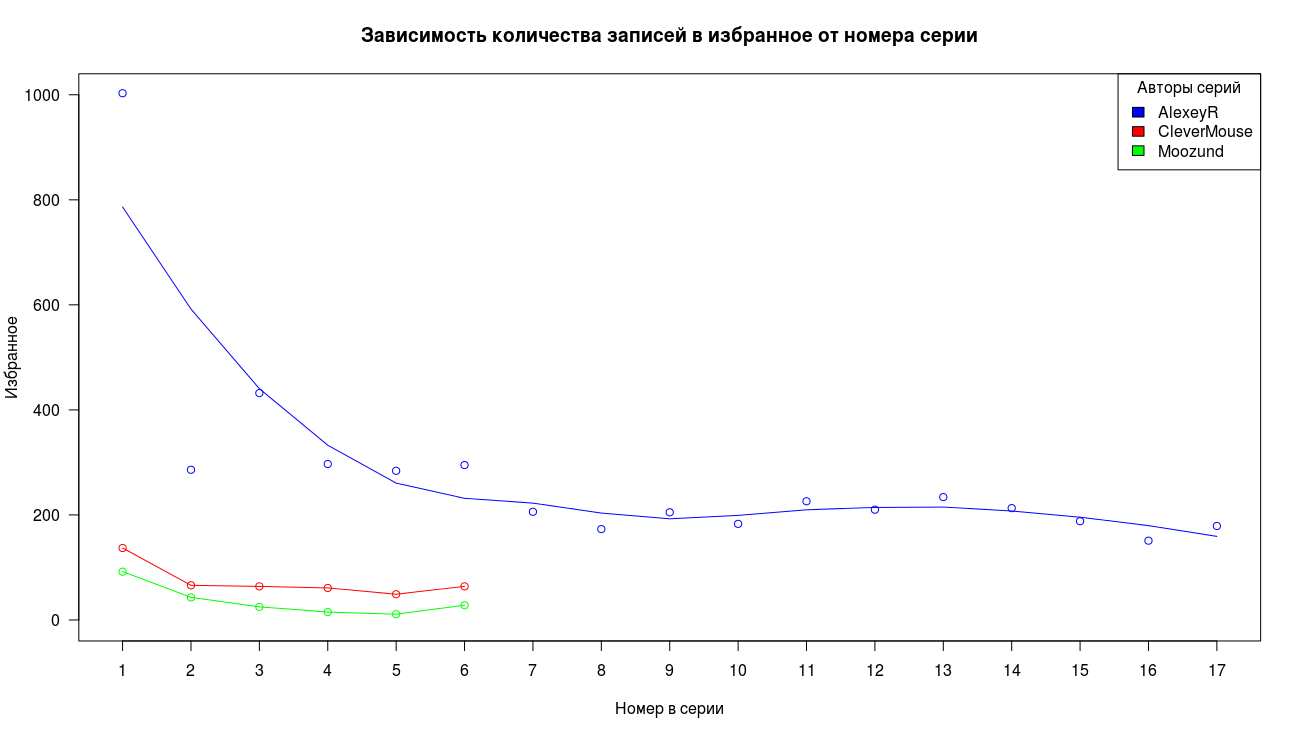
Ситуация с рейтингом отличается от двух графиков рассмотренных выше, но в целом общий вид картины сохраняется, за исключением низкого начального результата у синей серии. 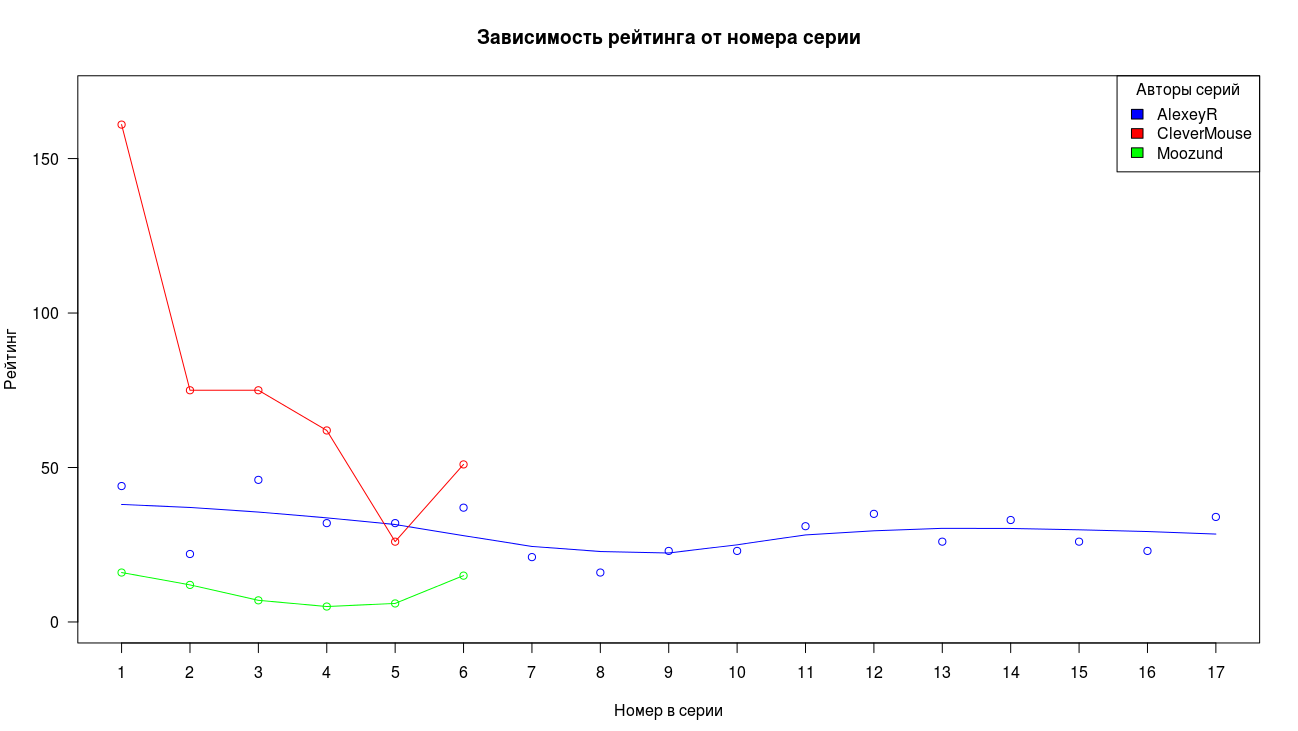
(получено с помощью скрипта long_plot.R)
Является результат столь неожиданным? На самом деле нет. Это примерно то, что и ожидалось в самом начале — как писали в предыдущей статье это классическое распределение Ципфа (интересным и менее сухим языком написано тут). Оно встречается довольно часто и неудивительно увидеть его при подсчете количества просмотров различных серий, например записей лекций: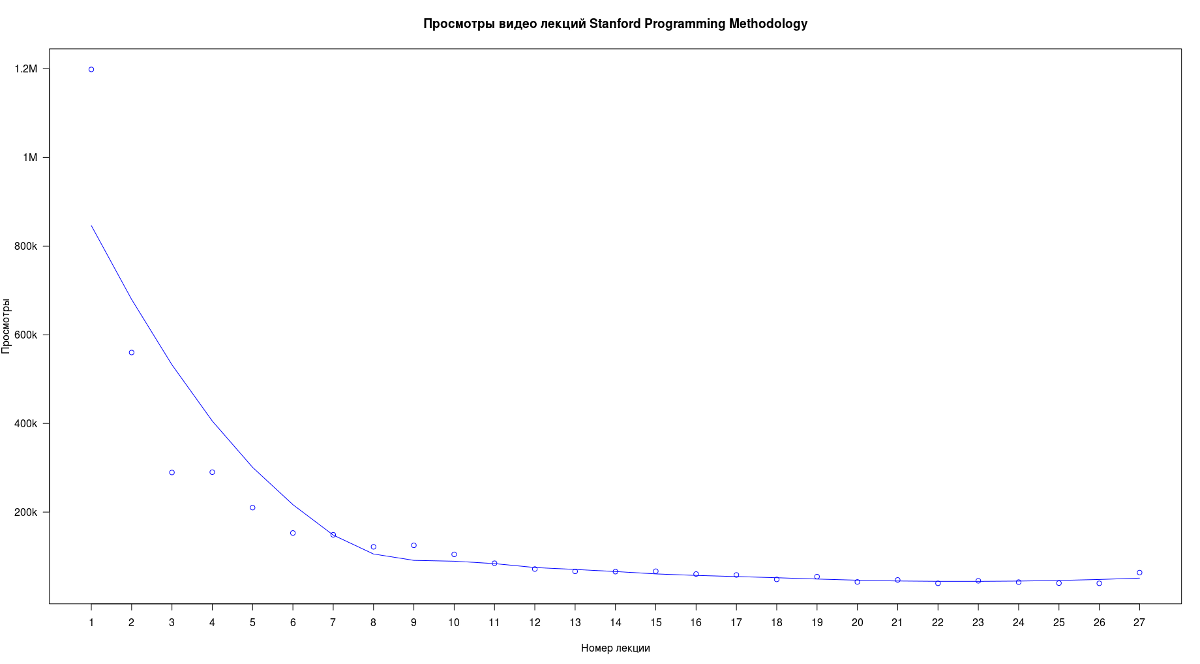
(данные взяты из youtube-канала курса Stanford Programming Methodology)
Мы видим схожую картину, когда при высоком значении параметра в первой точке, происходит резкое падение и «стабилизация» хвоста. Нельзя не отметить сходство зависимостей просмотров между статьями на хабре и просмотров материалов на других ресурсах в нескольких частях.
Заключение
Это эмпирическое наблюдение наталкивает нас на ряд интересных вопросов: возможно ли, что падение «интереса» к следующим частям кроется в самой структуре разбиения на части? Например, для просмотра статьиn требуется посмотреть n-1 статью, что существенно увеличивает время прочтения и снижает аудиторию. Играет ли роль какая-то специфика статей на хабре или это происходит со всеми схожими статьями на других ресурсах?
Безусловно нельзя следовать исключительно подобным эмпирическим наблюдениям для принятия решения нужно ли разделять статью на несколько частей или нет, но данное наблюдение позволяет задать некоторый стандарт ожидания (в основных параметрах) для следующих частей, основываясь на текущих показателях.
Дальнейшее чтение
Если тема анализа данных показалась интересной, то полезный материал для изучения
- Udacity
- Caltech — Learning from Data
- Coursera — Data Science Track
- Если вы живете в Санкт-Петербурге, то можно пройти курсы у DMLabs
- Если вы живете в Москве, то вы уже наверняка слышали про ШАД

