В блоге Moz известный итальянский SEO-специалист Жанлука Фиорелли (Gianluca Fiorelli) подверг сомнению существование 200 факторов ранжирования Google.

По мнению оптимизатора, полный и окончательный список 200 факторов ранжирования не существует. Тем не менее, до сих пор статистика его распространения, например в Buzzsumo, впечатляет:
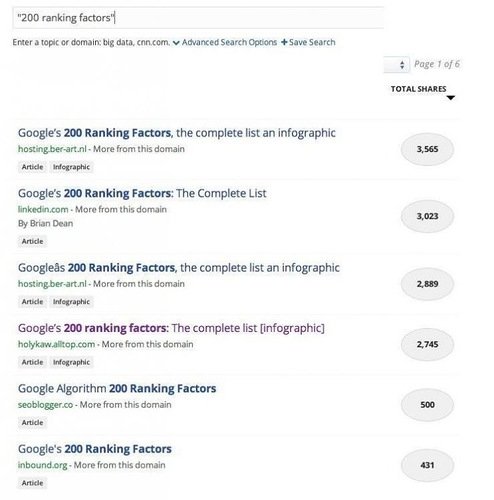
Согласно Фиорелли, целью написания его поста на эту тему была не критика взглядов авторов таких списков, в числе которых Брайан Дин (Brian Dean), который в августе опубликовал апдейт «полного списка» факторов, впервые представленного Backlinko в 2013 году. Он написал его потому, что эти списки, по его мнению, бесполезны и опасны. А также, он надеется помочь людям, особенно новому поколению оптимизаторов, понять, что окончательный и полный список факторов ранжирования Google не существует.
Более того, некоторые факторы, появляющиеся в таких списках:
- Являются мифами.
- Являются факторами корреляции, а не причинно-следственными факторами.
- Представлены с целью достичь цифру в 200 факторов.
Происхождение мифа
По словам Фиорелли, историю создания мифа о «200 факторах ранжирования Google» он узнал от своего друга, SEO-специалиста Джорджио Тавернити (Giorgio Taverniti).
Впервые Google, в лице Алана Юстаса (Alan Eustace), заявил, что он использует 200 факторов ранжирования, на пресс-дне 10 мая 2006 года:
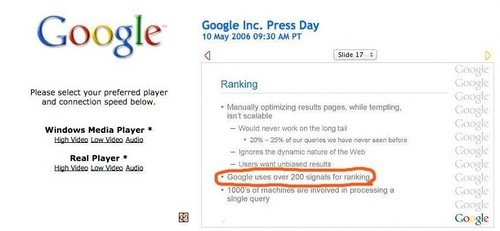
С учетом того, что точная фраза была «более 200 факторов ранжирования», можно сделать вывод, что «200» было приближенным числом.
Возможно, как предполагает Фиорелли, оно было предложено журналистам, чтобы объяснить сложность алгоритма Google. Если бы аудитория состояла из специалистов в области информационных технологий, вероятно, Юстас выразился бы по-другому.
Другим доказательством является тот факт, что в 2010 году Мэтт Каттс (Matt Cutts) собственнолично заявил, что, да, Google насчитывает более 200 факторов ранжирования, но каждый фактор имеет до 50 вариаций.
Важность понимания значения используемых терминов и слов
Многие SEO-специлисты, по словам Фиорелли, используют слова «ранжирование» («ranking») и индексирование («indexing») как синонимы, в то время как они являются совершенно разными концептами и стадиями работы поисковой системы.
«Индексирование» – одна из четырех взаимосвязанных и взаимозависимых фаз работы поисковой системы:
- Сканирование – сбор данных поисковым роботом (Crawling).
- Парсинг – синтаксический анализ сайтов (Parsing).
- Индексирование (Indexing).
- Поиск (Search).
Индексирование – это процесс обнаружения и картирования ресурсов всей сети, которые связаны со словом или фразой. Это то, что делают поисковые системы, но не поисковые оптимизаторы. Даже, если SEO-специалисты могут помочь работе поисковых систем, оптимизируя сайт.
Индекс, как объяснил Фиорелли Энрико Альтавилла (Enrico Altavilla), используется для определения, какие ресурсы следует предложить в качестве ответа на запрос и слова/фразы, из которых он состоит, а не в каком порядке их предложить — это уже функция фазы ранжирования.
Ранжирование – заключительный момент четвертой фазы – поиска.
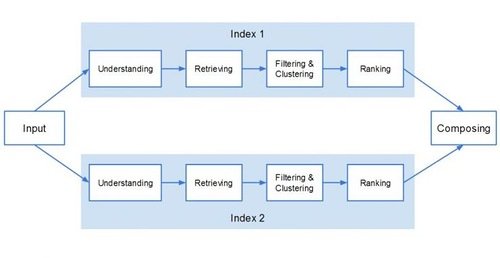
Контекст играет главную роль на стадии поиска и почти на каждом шаге этой стадии учитываются характеристики пользователей и устройств.
Как видно на изображении выше, поисковая фаза состоит из четырех различных стадий:
- Понимание входа, предоставляемого пользователем в виде запроса. Очень вероятно, что в этот момент работает алгоритм «Колибри» (Hummingbird), потому что Google для лучшего понимания входа модифицирует и расширяет запрос и только после этого переходит на вторую стадию.
- Извлечение документов из индекса, принимая во внимание команды типа «noindex».
- Фильтрация и кластеризация. Как только Google понял вход и извлек соответствующие документы из индекса, он применяет фильтры типа алгоритма «Панда» (Panda) и другие спам-фильтры, а также реже рассматриваемый фильтр Safe-Search и часто забываемый Private Search layer (персонализация).
- Ранжирование. На этой стадии Google применяет Х факторов ранжирования, но не ранее. И они должны быть рассмотрены и подсчитаны для каждого вида индекса Google:
- универсального поиска;
- поиска изображений;
- локального поиска;
- и т.д.
Не следует также забывать и тот факт, что контент и его расположение, формирующие SERP, зависят от многих вещей. Например, от используемого устройства.
Разбор конкретных пунктов списка факторов ранжирования
По словам Фиорелли, оптимизаторы любят списки факторов ранжирования. Они выступают не только потенциальным источником информации, но и обнадеживают. При том, что подобные списки являются всего лишь последовательностью мифов.
Для примера итальянский SEO-специалист предлагает взять «Список 200 факторов ранжирования Google», представленный Backlinko, как наиболее распространенный из опубликованных списков.
Фиорелли рассмотрел только 10 из указанных в списке факторов:
1. Плотность ключевых слов [Фактор ранжирования № 17]
По мнению Фиорелли, этот показатель никогда не был фактором ранжирования Google. Если он когда-либо и имел релевантность как фактор ранжирования, это было в Плейстоциновую эру поисковых машин.
Сейчас 2014 год, и Google только что отпраздновал свой 16-й день рождения.
По-прежнему очевидно, что имея ключевые слова, оптимизаторы хотят причислить их как фактор ранжирования к тексту интернет-документа. Однако также известно, что возможно сделать сайт ранжируемым по конкретным ключевым словам вообще без указания их на странице, если Google посчитает достаточно последовательными и релевантными внешние сигналы, связанные с ключевыми словами сайта.
2. Латентно-семантический индекс (LSI) [факторы № 18/19]
В этом примере Фиорелли процитировал Билла Славски (Bill Slawski), который в блоге Inbound.org написал следующее:
«Скрытое семантическое индексирование было изобретено в 1990 году, перед появлением всемирной паутины. Оно было разработано, чтобы помочь индексировать небольшие базы данных документов (менее 10 тыс. единиц).
Некоторые компании начали продажу инструментов генерирования ключевых слов для LSI (LSI Keyword generation tools), которые обещали, что могут помочь идентифицировать синонимы и слова с одинаковым или похожим значением.
Эта идея провалилась в том, что процесс LSI требует доступа к базе данных для вычисления, какие слова являются синонимами, – и единственные люди, имеющие доступ к базе данных Google для проведения такого анализа (что невозможно с того времени, как индекс Google стал слишком большим и изменяется слишком часто) – это сотрудники Google».
3. YouTube [фактор ранжирования № 76]
«Нет сомнения, что видео YouTube отдается предпочтение в поисковой выдаче».
Как это может быть фактором ранжирования? В конечном счете, это монополистическое использование Google своей собственной поисковой системы, но фактор ранжирования?
По мнению итальянского SEO-специалиста, это – классический пример того, как подобные списки претендуют на научность, но при этом они ненадежны и даже опасны.
4. Uptime сайта [фактор № 69]
«Долгое «отключение» вашего сайта из-за технических работ или проблем на сервере может навредить вашей релевантности».
Здесь, по мнению Фиорелли, автор списка прав: если Google после нескольких попыток увидит, что сайт возвращает ответ сервера 500, он начнет понижать его в выдаче.
Прав, но в случае, если говорить о проблеме индексирования, вызванной проблемой сканирования, а не ранжирования. Здесь Фиорелли еще раз упомянул о важности понимания точного значения употребляемых слов.
5. Ключевое слово в качестве первого слова в имени домена [фактор № 3]
Список факторов ранжирования включает этот фактор по той причине, что в 2011 году коллегия оптимизаторов посчитала, что EMD и PMD имели явное преимущество в ранжировании, и объявили об этом в исследовании факторов ранжирования Moz (Search Ranking Factors Survey).
В 2013 году Moz опубликовал новую редакцию данного исследования, и мнения тех же оптимизаторов разделились.
Самое главное – понимание того, что это были всего лишь мнения SEO-специалистов. Они могут рассматриваться (со всеми оговорками) как возможные, но с учетом того, что они основаны на личном опыте.
Любые мнения, даже авторитетные, – это всего лишь мнения, а не наука, не говоря о факторах ранжирования.
6. TLD (домен верхнего уровня) определенной страны [фактор № 10]
Это правда, что сTLD предлагает более сильную индикацию геотаргетинга Google, чем геотаргетированные вложенные папки и поддомены.
Однако, как может подтвердить любой SEO-специалист в мире, сайт с сTLD-доменом не обязательно ранжируется выше, чем сайт с родовым именем домена.
Неверно и то, что сайты с именами домена .es и .it не могут хорошо ранжироваться за пределами Google.es или Google.it.
Прошлой весной Фиорелли в посте в State of Digital приводил много примеров, когда сайты с латиноамериканскими сTLD ранжировались выше, чем сайты с доменным именем .es в Google.es. В комментариях к посту видно, что это распространенная ситуация в каждой региональной версии Google.
Этот «фактор ранжирования» – наглядный пример того, как подобные списки могут смешивать правильную информацию и опасное неведение (в значении «отсутствие знаний или информации по данной теме»).
7. Использование Google Analytics и Инструментов для вебмастеров Google (Google Webmaster Tools) [фактор № 78]
«Некоторые считают, что имея эти две программы, установленные на сайте, можно улучшить индексирование его страниц. Они также могут непосредственно влиять на позицию сайта в выдаче, предоставляя Google больше данных…»
«Некоторые считают»? Кто? Студент, разглагольствующий на форуме? Специалист по информационным технологиям? По мнению Фиорелли, это – чистой воды спекуляция.
8. Посты от гостей сайта [фактор № 91]
Если говорить о том, насколько опасны могут быть посты гостей сайта, то речь идет о спаме.
Таким образом, если ссылка (или серия ссылок) из постов гостей рассматривается как имеющая манипулятивную природу, следует говорить о спам-фильтрах (третьей стадии поиска), а не о ранжировании. Опять же, важно понимание значений употребляемых слов, подчеркнул Фиорелли.
9. Количество лайков страницы и количество пользователей, поделившихся ссылкой на страницу, в Facebook [фактор № 157/158]
Google не может видеть лайки и репосты в Facebook. Поэтому они не могут быть фактором ранжирования.
Об этом же сказал и Мэтт Каттс:
«Нам нравятся стандарты, которые доступны в открытом интернет-пространстве. Если мы не способны просканировать что-либо – типа Facebook – мы не хотим зависеть от таких данных».
Наибольшая ошибка здесь – неразбериха между причинно-следственной связью и корреляцией. Сила социальных сигналов – это сила корреляции.
Фиорелли комментировал ранее в посте Маркуса Тобера (Marcus Tober) в Moz, что репосты в социальных сетях не являются прямой причиной хороших позиций ресурса в выдаче, но могут помочь их получить:
Репосты в социальных сетях > лучшая видимость > создание второго эшелона обратных ссылок > улучшенные возможности для получения органических обратных ссылок от пользователей, обнаруживших контент, которым поделились другие.
10. Сотрудники в LinkedIn [фактор № 171]
Здесь, по мнению Фиорелли, – предел абсурда.
Backlinko определяет сотрудников, указанных в социальной сети LinkedIn, в качестве сигнала популярности бренда. Проблема в том, что сигнал брендинга не является сигналом ранжирования.
Автор списка ссылается на старый пост Рэнда Фишкина (Rand Fhiskin), написанный в 2011 году. Но в том посте речь шла совершенно о другом. Рэнд представил свою (верную) гипотезу, что в будущем Google начнет обращать внимание на сигналы «брендинга» в порядке создания именованных объектов, способных отражать оффлайн-релевантность в онлайн-присутствии.
В том посте Рэнд никогда не указывал сотрудников в LinkedIn в качестве фактора ранжирования.
На этих 10 пунктах списка 200 факторов ранжирования Фиорелли остановился, отметив, что мог бы указать на большее количество заблуждений и ошибок.
Тем не менее, по его словам, его намерение – не разобрать полностью список, а показать SEO-специалистам и, особенно, их молодому поколению, что использование подобных списков не приносит пользы. Его цель – призвать людей не создавать их.
«Все ли списки факторов ранжирования плохие? — Нет», — отвечает на свой же вопрос Фиорелли.
Он считает, что можно найти серьезные исследования, нацеленные на понимание, почему конкретные сайты ранжируются выше, чем другие.
Исследование факторов ранжирования Moz, упомянутое ранее, и Searchmetrics Ranking Factors study – наиболее цитируемые примеры таких исследований.
Тем не менее, существует огромная разница между исследованиями и простой инфографикой/ постами, куда входят и предполагаемые «200 факторов ранжирования»: они являются корреляционными исследованиями, проведенными вслед за научными.
Следовательно, они всего лишь сообщают об общих характеристиках сайтов, которые высоко ранжируются в SERP. Их можно использовать в качестве примера лучших практик для использования, если они применимы к сайту, но не более того, считает Фиорелли.

