Содержание
Все животные равны, но некоторые животные равнее других. Скотный Двор, Джордж Оруэлл (оригинал).
Достаточно много статей на хабре набирает существенное количество комментариев, e.g. в статьях «лучшее за месяц» их, как правило, более сотни. За годы чтения хабра, создалось впечатление, что примерно в половине случаев для комментариев первого уровня получается вот такая вот картина
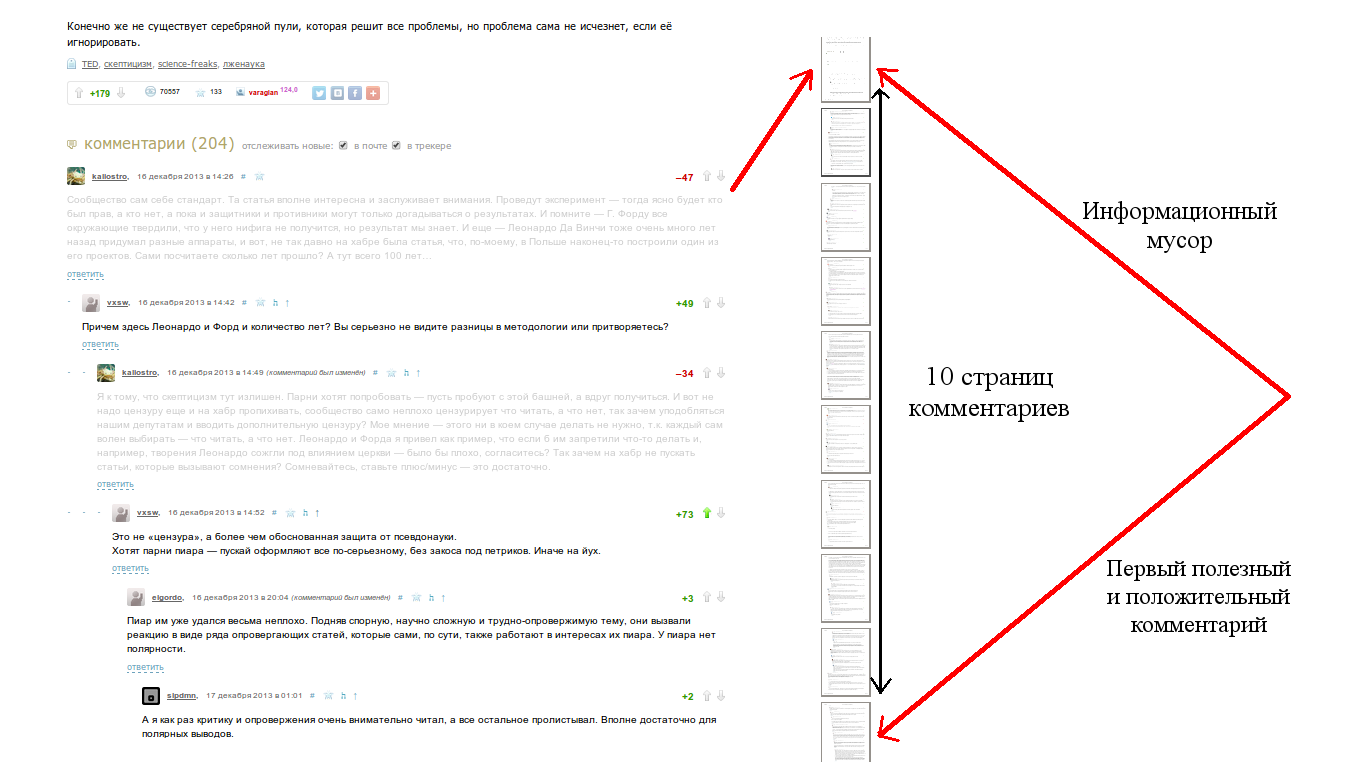
(картинка сделана на основе хабра-статьи «Список скептика»).
Под катом рассказ, какие бывают сортировки комментариев, где они применяются и краткое рассуждение о том, как вообще можно сортировать комментарии (и зачем).
Вообще говоря проблема сортировки комментариев, постов и всего остального не нова: инфографика от фейсбука, сортировка комментариев на reddit тут и тут и краткое описание параметров алгоритма от digg.
Основные методы сортировки комментариев первого уровня
Пойдем от простого к сложному, кратко описывая и характеризуя методы. Начнем с самых простых и наивных методов: усреднения и его вариаций (подробности описаны здесь).
Здесь и далее, кроме отдельно оговоренных случаев, под комментарием мы понимаем «комментарий верхнего уровня». Смысл примерно в следующем, комментарии верхнего уровня адресуются самой статье, а комментарии второго, третьего и тд — это дискуссия вокруг комментария. Методы, учитывающие всю ветку комментариев, кратко обсудим в конце статьи.
Задача состоит в том, чтобы приписать комментариям некоторое число score (вес комментария) и по этому параметру отсортировать весь список.
Количество плюсов минус количество минусов

Такое применяют в онлайн-словаре urbandictionary.
Этот метод является самым простым, но далеко не самым соответствующим ожиданиям пользователей. Например, на картинке выше мы видим, что описание у которого 72% процента положительных оценок, размещено ниже, чем описание у которого 70% процентов положительных оценок.
Относительная средняя оценка: количество плюсов к общему числу оценок
Одна из опций сортировки на амазоне — это относительная средняя оценка. Допустим, мы ищем тостер и включили сортировку по отзывам пользователей:
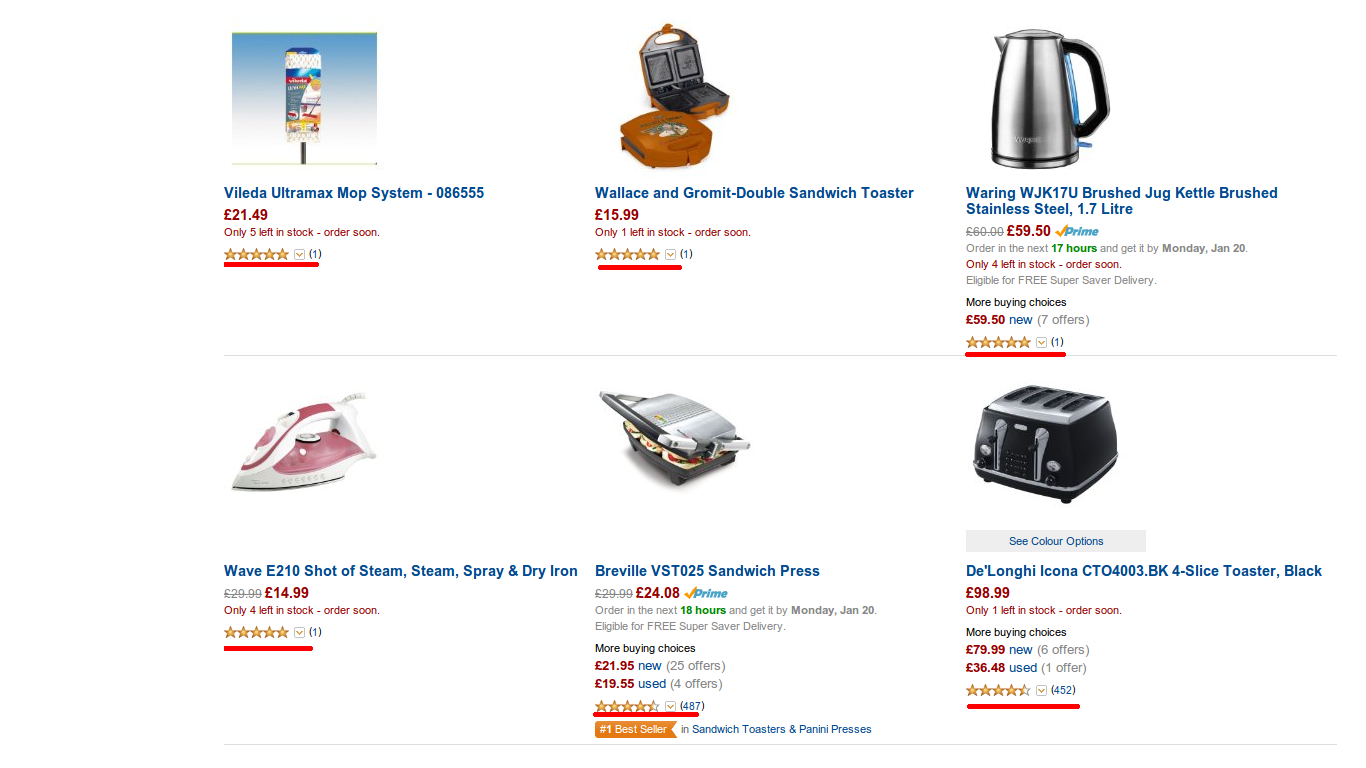
Получается, что элемент с единственным голосом в 5*, всегда будет находиться выше любого элемента, у которого есть хотя бы одна любая другая оценка (4*, 3*, 2*, 1*), независимо от числа этих оценок. Проще говоря, если у нас есть товар у которого стоит 9999 оценок 5* и одна в 4*, то этот товар будет находиться ниже, чем товар с единственной оценкой в 5*.
Вероятность ожидания положительной оценки
Перед выборами всегда происходят опросы общественного мнения, где по небольшому количеству опрощенных пытаются восстановить общую картину мира. По небольшому доступному нам количеству измерений, мы пытаемся понять следующее, имея наблюдаемое количество оценок (плюсы и минусы к товару), с вероятностью по крайней мере в 0.85, какая «действительная доля» положительных оценок?
Как обычно вычисляются подобные вещи доступным языком написано в книге:
Probabilistic Programming & Bayesian Methods for Hackers
Если говорить кратко, то проведение подобных вычислений слишком трудозатратно, поэтому пользуются формулой для нижней границы доверительного интервала Вилсона (т.е. приходится использовать оценочное значение):
p̂ — это наблюдаемое относительное число плюсов, n — общее количество оценок, zα/2 — берется из таблиц, это квантиль (1- α/2) стандартного нормального распределения (для 15% z=1 — 85% confidence, для 5% z=1.6 — 95% confidence)
Если вам кажется, что сверху написано что-то в таком духе:
То понятным языком и в деталях это описано здесь, в конце здесь и лучше всего это описано здесь. Там же можно найти короткие и понятные имплементации описанного метода (и много других проясняющих картинок).
В различных вариациях, данный метод, как часть алгоритма ранжирования используют reddit, digg and yelp.
Объяснение и пример от Randal Munroe (автора xkcd, он же внедрил этот алгоритм в reddit):
Если у комментария только один плюс и ноль минусов, то относительное число плюсов 1.0, но так как данных мало [n — прим. автора], система расположит его в конце списка. А если у него 10 плюсов и один минус, то у системы будет достаточно уверенности [по смыслу — доказательства; подтверждающих данных], что разместить данный комментарий выше чем комментарий с 40 плюсами и 20 минусами — просчитывая, что к тому времени, как комментарий получит 40 плюсов, почти наверное у него будет меньше 20 минусов. И главная прелесть системы в том, что если она ошибается (в 15% случаев), она быстро получит достаточно данных, чтобы комментарий с меньшим количеством данных оказался на самом верху.
Вообще интуиция, у подобных методов Байесовского вывода, состоит в следующем: у нас есть некоторая догадка, как в среднем голосуют за посты, например, получить плюс можно с вероятность 0.7, а минус с вероятностью 0.3 — этакая испорченная монетка. Получив новую порцию информации по конкретной монетке, мы корректируем наше представление о ней по правилу Байеса:
![]()
где H — гипотеза (Hypothesis), E — обозреваемые данные (Evidence), P(E|H) = вероятность получить результат E, если верна гипотеза H, вместе они дают нам возможность сказать, какого вероятность гипотезы H при обозреваемом результате E.
Новые параметры в сортировке
Рассмотренные выше алгоритмы используют только количество плюсов и минусов. В данной части мы разберемся, а какие еще параметры могут влиять на ранжирование комментариев.
Основными источниками буду служить следующие статьи:
Reddit, Stumbleupon, Del.icio.us and Hacker News Algorithms Exposed!
How Hacker News ranking algorithm works
How Reddit ranking algorithms work
Время
Зачем кому-то вообще может потребоваться использовать время, кроме как в хронологической сортировке? Представим, что мы переходим в статьи по ссылке из «Что обсуждают?» довольно логично (хотя конечно как и другие оценочные суждения, спорно), что пользователь ожидает дискуссию и свежие комментарии, именно благодаря им статьи и попадают в данный раздел.
Как с этим обстоит у других крупных сайтов с пользовательским контентом? Мы рассмотрим reddit и hacker news
Алгоритм reddit для постов
Reddit использует два разных алгоритма ранжирования: один для постов, второй для комментариев. Для комментариев используется описанный выше вариант с нижней границей доверительного интервала Вилсона, а вот для постов время учитывается:
кратко опишем алгоритм
Пусть A — это время в секундах, когда пост был опубликован, B — время создания ресурса reddit в секундах, тогда t
t = A — B
т.е. относительное время жизни поста в секундах.
x = разница между числом плюсов и минусов поста.
z = |x|, если x != 0, иначе z = 1.
![]()
Алгоритм hacker news
Данный ресурс использует один и тот же алгоритм для сортировки комментариев и постов.
Пусть t — это количество часов с момента публикации, v — количество голосов, G — константа (говорят, по умолчанию она 1.8):
![]()
И зачем козе баян?
Казалось бы, в случае с комментариями оценок должно хватать и время не должно играть существенной роли. С другой стороны, когда количество комментариев растет многие пользователи просто не добираются до самого конца (попробуй пролистай 300-400 комментариев). Возможная альтернатива — сортировать не по одному, а по нескольким параметрам т.е. учитывать время при прочих равных. Например, если все комментарии имеют 0 голосов, тогда «свежие комментарии» предпочтительней старых, так как у старых было время набрать некоторое количество плюсов, и если они их не набрали, то возможно стоит отдать предпочтение новым комментариям.
Альтернативно, мы можем использовать время, как небольшой элемент затухания (weight decay) в функции ранжирования, например, как в постах reddit или комментариях hacker news.
Ранжирование с учетом всей ветки
Естественным препложением будет учитывать комментарии в одной ветке с некоторым весом в зависимости от их уровня\позиции в ветке (в тривиальном случае, мы можем рассматривать всю ветку, как множество равноправных комментариев т.е. с одинаковым весом). Допустим, что vi+ — это количество плюсов у комментария i (та же нотация для минусов), а li — это уровень вложенности комментария i, а I — это множество всех индексов комментария в ветке, тогда мы можем предложить простейшее обобщение первого метода с учетом всей ветки:
(здесь мы подразумеваем, что vi+, li — это на самом деле функции, возвращающие сколяр по индексу комментария, поэтому их нет во входных данных).
Подобным (наивным) образом можно обобщить и другие методы ранжирования комментариев. Зачем это нужно? Если мы считаем, что не только комментарий первого уровня важен при ранжировании, а, например, вся дискуссия имеет значение, то действительно важно ранжировать всю ветку. Если мы обратим внимание на картинку в начале статьи, то несмотря на «сильно заминусованный» первый комментарий (и как я считаю, за дело), вокруг него в первой ветке выросла довольно интересная дискуссия.
Вес и профиль пользователя(ей)
Точный алгоритм digg не известен широкой публике, но по крайней мере мы знаем, какие примерно параметры туда входят (источник по алгоритму):
- Количество голосов с учетом временного окна: много голосов за короткий промежуток, лучше чем много голосов за длительный промежуток
- Источник ссылки (эт специфично для digg, новости указывают на определенный сайт с источником): как часто статьи из этого источника попадают в топ? (получают плюсы)
- Профиль автора
- Время отправления: если куча народу одновременно плюсуют статью в три утра, что-т может быть тут не так [спорный параметр, не правда ли? — прим. автора]
- Наличие похожих ссылок на самом digg (дубликаты)
- Профили голосующих
- Количество комментариев
- Количество просмотров
- ….
В общем, сложный у них похоже алгоритм. Но что мы можем в принципе почерпнуть из него? Можно по разному учитывать комментарии и вес голосов к постам в зависимости от различных параметров и достаточное количество этих параметров уже известно из алгоритмов других ресурсов.
Во многом схожая идея с временем, как с дополнительным параметром: при прочих равных при ранжировании комментариев, можно учесть вес пользователя (или даже его вклад в определенный хаб), таким образом, если поступает много комментариев к статье, то «авторитетное мнение» поднимется выше остальных и будет доступно к прочтению.
Заключение
Ранжирование комментариев — это популярный и часто полезный элемент многих ресурсов. Нужно ли это на хабре вопрос неоднозначный, но вполне достойный обсуждения и возможно экспериментов. Действительно ли проблема с изобилием комментариев к определенным статьям существует? Если нет, то появится ли она в будущем? Нужны ли какие-то другие инструменты сортировки?
Но всегда стоит помнить, что для любого ресурса главное — это не сортировка комментариев, а качества контента.
Перепост: http://habrahabr.ru/post/209552/

