Вступление
Когда мы приходим к потенциальным заказчикам рассказывать про сервис персонализации crossss, один из частых вопросов: «А как он внутри устроен-то?». Пользуясь дружественным блогом компании CentroBit, расскажу немного теорию и практику устройства рекомендательных сервисов.

Получилось так, что по ходу написания статья стала становиться уж слишком большой, поэтому я решил ограничиться сейчас первой частью, после которой придется написать как минимум еще одну, а то и две.
Начнем с самых азов и философии.
Что такое персонализация?
“If I have 3 million customers on the Web, I should have 3 million stores on the Web.” –Jeff Bezos, CEO of Amazon.com
Лента, которую вы видите на фейсбуке или вконтакте – только ваша, другой такой нет ни у кого. Почему же все остальные сайты одинаково выглядят для меня и для вас? Ответ в том, что соцсети естественным образом персонализованы, а остальные сайты, как правило, нет.
Таким образом, персонализация интернет-сайта – это его автоматическая подстройка под текущие нужды конкретного посетителя.
В персонализации можно разделить два противоположных подхода.
Первый – расширяющая персонализация, когда на основе некоторого знания о пользователе ему предлагается дополнительная информация, предположительно ему полезная. Характерным примером являются товарные рекомендации, чаще всего встречающиеся в интернет-магазинах, например, с надписью «С этим товаром покупают».
Второй – сужающая персонализация. Характерным примером ее является алгоритм ленты фейсбука, который из потока постов френдов отбирает и показывает пользователю лишь те посты, которые предположительно более всего его вовлекут.
Два этих подхода решают противоположные задачи. Первый – предлагает ранее неизвестную информацию. Второй – наоборот, спасает от перегрузки информацией.
Что такое рекомендационная система?
Рекомендационная система – это программный комплекс, который определяет интересы и предпочтения посетителя и дает рекомендации в соответствии с ними.
Существуют различные подходы к разработке рекомендационных систем, которые могут применяться в зависимости от:
• доступных данных о пользователях и рекомендуемых сущностях
• видов явного и неявного фидбека пользователей
• предметной области
При этом целью классической рекомендационной системы является рекомендация товаров, ранее неизвестных пользователю, но ему полезных или интересных в текущем контексте.
Другими словами, рекомендационная система отвечает на вопрос о конкретном посетителе сайта: «Какой продукт этот посетитель захочет купить прямо сейчас?»
На эту основную цель рекомендационной системы могут быть несколько разных точек зрения, обуславливающих разные критерии оценки успешности рекомендационной системы:
С точки зрения посетителя – насколько ему нравятся рекомендованные товары. Метрики этого – качество аппроксимации оценки или CTR рекомендационной системой и доля посетителей, купивших рекомендованный товар.
С точки зрения интернет-магазина или интернет-издания – максимизация ожидаемого дохода с пользователя или глубины просмотра.
Парадигмы рекомендационных систем
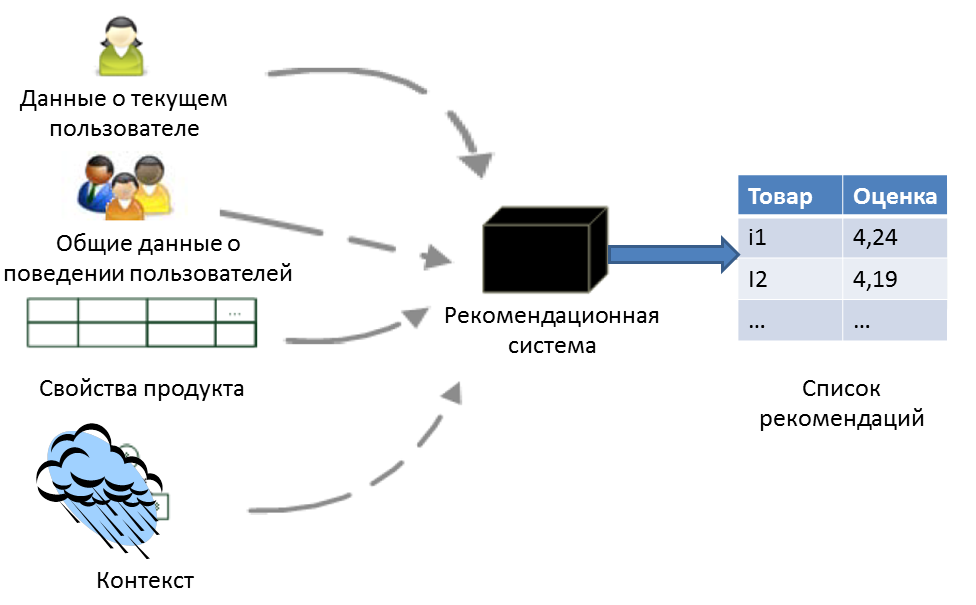
Идеальная рекомендационная система для построения рекомендаций использует данные о текущем пользователе, о поведении всех пользователей в целом, о свойствах рекомендуемых продуктов и о контексте текущего интереса пользователя. Так, например, поступаем мы в http://crossss.ru. Но для этого необходимо обрабатывать гигантские массивы данных, поэтому исторически, пока такой возможности не появилось буквально несколько лет назад, рекомендационные системы использовали подмножества такого массива данных. И сегодня такие системы встречаются еще довольно часто.
Опишу основные подходы к построению рекомендационных систем для интернет-магазинов и интернет-изданий.
Рекомендации, подбираемые вручную
Если посмотреть на рекомендационные блоки в российских интернет-магазинах, то большинство из них – это вручную заполненные списки связанных товаров. Если товарный ассортимент невелик и меняется редко, то это может быть неплохим выходом. Если он велИк, а связи между товарами неочевидны, то подбирать рекомендации становится чрезмерно трудоемко, либо они становятся неэффективными.
Контентные рекомендационные системы
Системы, основанные исключительно на свойствах продуктов, называются контентными.
Например, широко распространен (более 2 миллионов установок) плагин к WordPress Yet Another Related Posts Plugin(YARPP). В видео http://wordpress.tv/2011/01/29/michael-%E2%80%9Cmitcho%E2%80%9D-erlewine-the-yet-another-related-posts-plugin-algorithm-explained/ автор разъясняет принцип его работы.
Другим, чисто российским, и вполне уникальным примером контентной рекомендационной системы являетсяhttp://similar4.ru/ компании Кузнеч. В ней рекомендуемые одежда и обувь подбираются по принципу визуального подобия текущему предмету.
Разберем чуть более подробно, как устроен контентный рекомендательный движок опенсорсной рекомендационной системы easyrec (http://easyrec.sourceforge.net).
В eacyrec в общий фреймворк можно встраивать различные рекомендательные движки в качестве плагинов. Это, в частности, связано с тем, что easyrec (судя по всему) используется в качестве фреймворка коммерческой системой SmartEngine, имеющей около 10 клиентов в России и клиента в Сингапуре (хотя разработчики — австрийцы).
Одним из 4 алгоритмов, имеющихся в опенсорсной поставке easyrec, является калькулятор мер подобия профилей товаров (Profile Similarity Calculator). Для его работы требуются профили товаров, в которых хранятся свойства товаров.
Профили товаров описываются, например, так:

Эти свойства товаров загружаются плагином, и для вычисления меры подобия каждого из свойств товаров используется быстрый дедупликатор duke. Он использует компараторы для сравнения каждого из свойств. Компаратор должен выдавать 0, если свойства совершенно не похожи, и 1, если идентичны. Например, если вы хотите сравнить две строки, вы можете использовать ExactComparator, который возвращает 1, если строки идентичны, и 0 – в обратном случае. Альтернативно можно использовать компаратор по расстоянию Левинштейна (специально поставил отдельную ссылку на Владимира Иосифовича), взвешенному расстоянию Левинштейна, мере Яро-Винклера, Q-грамам, а также множеству специализированных мер, начиная с численной и кончая геопозицией и фонетическим сравнением.
Из индивидуальных мер подобия свойств выводится общая мера подобия товаров. Для каждой пары товаров, для которой мера подобия превышает некоторый порог, устанавливается рекомендационная связь между товарами (если такая связь есть между товарами A и B, то А рекомендуется к B, и наоборот).
Плюсы и минусы таких рекомендационных систем вполне понятны. С одной стороны, они относительно легки вычислительно – пересчет релевантности предметов/статей производится при добавлении новых предметов, что происходит нечасто. При этом всем посетителям показываются одни и те же рекомендации. С другой стороны, предположение о том, что текущая страница полноценно определяет потребности пользователя, является в большом числе случаев преувеличением.
Коллаборативная фильтрация товаров(Item-To-Item Collaborative Filtering)
Методы коллаборативной фильтрации (Collaborative filtering — CF) генерируют рекомендации на основе данных об оценках или использовании товаров (покупке товаров, просмотре фильмов, прочтении статей) безотносительно к характеристикам конкретного товара.
В основе коллаборативной фильтрации товаров, как и в основе контентных систем, лежит идея о том, что интерес к определенному товару есть показатель того, что пользователю также будет интересен и другой товар (как заменяющий либо дополняющий текущий товар). Оставлю уважаемым читателям обдумать, в каких пределах верно это предположение.
Популярность такие методы получили после того, как как в начале 2003 года сотрудники Амазона Greg Linden, Brent Smith и Jeremy York опубликовали в журнале IEEE INTERNET COMPUTING заметку об устройстве рекомендационной системы АмазонаAmazon.com Recommendations: Item-to-Item Collaborative Filtering.
Для того, чтобы получить рекомендации, системы коллаборативной фильтрации товаров увязывают две основных сущности: пользователей и товары. Простейший способ связи – это явно указанный пользователем рейтинг (оценка) товара.
Если у нас есть данные об оценке товаров различными пользователями, то мы получаем матрицу пользователь – товар:

Вопрос: какой товар порекомендовать, если пользователь сейчас смотрит Товар1? Ответ, даваемый Item-to-Item CF: тот, который больше всего похож на Товар1. На более математическом языке это значит, что есть метрика близости между товарами, основанная на оценках пользователей.
Простейшей мерой близости является косинус угла между соответствующими векторами оценок для товара пользователями:
Например, в нашем случае, косинусы между вектором Товара1 и других товаров такие:
Таким образом, самым близким по нашей метрике к Товару1 является Товар5.
Однако в реальных приложениях начинают возникать сложности, связанные, например, с тем, что разные товары оценивает разное число пользователей, а оценки каждого пользователя зачастую сдвинуты в одну из сторон. Для того, чтобы обойти эту проблему, можно применить модифицированную косинусную метрику:
где U – множество пользователей, оценивших как a, так и b.
Дальнейшие проблемы возникают, когда в крупных приложениях обнаруживается, что получить оценку от каждого пользователя может лишь крайне небольшое число товаров. Таким образом, к явным оценкам надо добавлять неявные, основанные на том, какие товары как долго посетитель просматривал, какие покупал и т.д. Естественно, интерпретация неявных данных – более сложная задача, и ее решение всегда приближено, а значит, приводит к появлению шума.
Таким образом, в реальных задачах матрица пользователь – товар получается
1. Огромной
2. Очень разреженной
3. Зашумленной
К счастью, прикладная математика давно знает, что делать с такими матрицами. А именно, сингулярное разложение замечательно тем, что оно оптимально приближает заданную матрицу ![]() другой матрицей
другой матрицей ![]() меньшего ранга .:
меньшего ранга .:
где матрицы ![]() ,
, ![]() и
и ![]() получаются из соответствующих матриц в сингулярном разложении матрицы
получаются из соответствующих матриц в сингулярном разложении матрицы ![]() обрезанием до ровно первых столбцов (элементы матрицы
обрезанием до ровно первых столбцов (элементы матрицы ![]() упорядочены по невозрастанию).
упорядочены по невозрастанию).
Таким образом, мы выполняем своего рода сжатие информации, содержащейся в ![]() . Это сжатие происходит с потерями — в приближении сохраняется лишь наиболее существенная часть матрицы
. Это сжатие происходит с потерями — в приближении сохраняется лишь наиболее существенная часть матрицы ![]() , а шум отфильтровывается. Еще один взгляд на такую аппроксимацию состоит в том, что все товары проецируются в пространство меньшей размерности , в которой и определяется расстояние между ними.
, а шум отфильтровывается. Еще один взгляд на такую аппроксимацию состоит в том, что все товары проецируются в пространство меньшей размерности , в которой и определяется расстояние между ними.
По примерно такой схеме работает довольно большое число рекомендательных систем.

